
Sys.time()[1] "2023-08-12 00:19:41 CDT"Reprogram-Seq leverages organ-specific cell atlas data with single-cell perturbation and computational analysis to predict, evaluate, and optimize TF combinations that reprogram a cell type of interest.
Sys.time()[1] "2023-08-12 00:19:41 CDT"[1] "America/Chicago"Load required packages.
`%+replace%` <- ggplot2::`%+replace%`PROJECT_DIR <- file.path(
"/Users/jialei/Dropbox/Data/Projects/UTSW/Cellular_reprogramming",
"Cardiac_reprogramming/Notebooks"
)gene_symbols <- vroom::vroom(
file = file.path(
PROJECT_DIR, "data", "misc", "genes.tsv"
),
col_names = FALSE
)
gene_symbols <- setNames(object = gene_symbols$X2, nm = gene_symbols$X1)
gene_symbols |> head()ENSMUSG00000051951 ENSMUSG00000089699 ENSMUSG00000102343 ENSMUSG00000025900
"Xkr4" "Gm1992" "Gm37381" "Rp1"
ENSMUSG00000109048 ENSMUSG00000025902
"Rp1" "Sox17" length(gene_symbols)[1] 27999matrix_readcount_use <- Matrix::sparseMatrix(
i = readRDS(
file.path(
PROJECT_DIR, "data/10x", "expr_readcount_raw_csc_indices.rds"
)
),
p = readRDS(
file.path(
PROJECT_DIR, "data/10x", "expr_readcount_raw_csc_indptr.rds"
)
),
x = readRDS(
file.path(
PROJECT_DIR, "data/10x", "expr_readcount_raw_csc_values.rds"
)
),
dims = readRDS(
file.path(
PROJECT_DIR, "data/10x", "expr_readcount_raw_csc_shape.rds"
)
),
dimnames = readRDS(
file.path(
PROJECT_DIR, "data/10x", "expr_readcount_raw_csc_dimnames.rds"
)
),
index1 = FALSE
)dim(matrix_readcount_use)[1] 27999 34564rownames(matrix_readcount_use) <- paste(
rownames(matrix_readcount_use),
gene_symbols[rownames(matrix_readcount_use)],
sep = "_"
)
matrix_readcount_use[1:5, 1:5] |>
as.matrix() |>
knitr::kable()| BL5_AAACCTGCACTACAGT | BL5_AAACCTGCAGTACACT | BL5_AAACCTGGTTCACGGC | BL5_AAACCTGGTTGCTCCT | BL5_AAACCTGTCCAACCAA | |
|---|---|---|---|---|---|
| ENSMUSG00000051951_Xkr4 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000089699_Gm1992 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000102343_Gm37381 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000025900_Rp1 | 0 | 0 | 0 | 0 | 0 |
| ENSMUSG00000109048_Rp1 | 0 | 0 | 0 | 0 | 0 |
dim(monocle2_result$data)[1] 22693 11Check memory usage.
purrr::walk(
list(matrix_readcount_use, monocle2_result), \(x) {
print(object.size(x), units = "auto", standard = "SI")
}
)1.1 GB
3.5 MBx_column <- "x_monocle"
y_column <- "y_monocle"
GEOM_POINT_SIZE <- 0.5
EMBEDDING_TITLE_PREFIX <- "Monocle"
RASTERISED <- FALSEembedding <- monocle2_result$data |>
dplyr::mutate(
group = dplyr::case_when(
category %in% c("BL18") ~ "10F, D14",
category %in% c("BL19") ~ "3F, D7",
category %in% c("BL5", "BL6") ~ "Primary",
category %in% c("BL7") ~ "Uninfected",
category %in% c("BL8") ~ "10F, D7"
),
group = factor(
group,
levels = c(
"Primary", "Uninfected",
"10F, D7", "10F, D14", "3F, D7"
)
)
) |>
dplyr::rename(cell = sample_name)p_embedding_pseudotime <- plot_embedding(
data = embedding[, c(x_column, y_column)],
color = embedding$pseudotime,
label = glue::glue("{EMBEDDING_TITLE_PREFIX}; Pseudotime"),
color_legend = TRUE,
sort_values = TRUE
) +
theme_customized_embedding()
color_labels <- embedding |>
dplyr::group_by(state) |>
dplyr::summarise(
x = median(x_monocle),
y = median(y_monocle)
) |>
as.data.frame()
geom_segment_layer <- ggplot2::geom_segment(
ggplot2::aes_string(
x = "source_prin_graph_dim_1",
y = "source_prin_graph_dim_2",
xend = "target_prin_graph_dim_1",
yend = "target_prin_graph_dim_2"
),
data = monocle2_result$edge,
na.rm = TRUE,
color = "#2196F3",
linetype = "solid",
linewidth = .25
)Warning: `aes_string()` was deprecated in ggplot2 3.0.0.
ℹ Please use tidy evaluation idioms with `aes()`.
ℹ See also `vignette("ggplot2-in-packages")` for more information.layers <- list(
ggplot2::geom_point(
data = color_labels,
aes(x, y),
size = 2.0,
stroke = 0,
shape = 22,
fill = "#E29C36",
color = "#E29C36"
),
ggplot2::annotate(
geom = "text",
x = color_labels$x,
y = color_labels$y,
label = LETTERS[as.integer(color_labels$state)],
size = 1.5,
family = "Arial",
color = "black"
)
)
p_embedding_pseudotime <- p_embedding_pseudotime +
geom_segment_layer +
layersp_embedding_UMI <- plot_embedding(
data = embedding[, c(x_column, y_column)],
color = log10(Matrix::colSums(matrix_readcount_use[, embedding$cell])),
label = glue::glue("{EMBEDDING_TITLE_PREFIX}; UMI"),
color_legend = TRUE,
sort_values = FALSE,
shuffle_values = TRUE
) + theme_customized_embedding() +
geom_segment_layerp_embedding_backbone <- ggplot2::ggplot() +
ggplot2::facet_wrap(NA) +
geom_segment_layer +
theme_customized_embedding() +
scale_x_continuous(
limits = extract_ggplot_axis_ranges(p_embedding_pseudotime)[[1]]
) +
scale_y_continuous(
limits = extract_ggplot_axis_ranges(p_embedding_pseudotime)[[2]]
) +
layersp_embedding_MT <- plot_embedding(
data = embedding[, c(x_column, y_column)],
color = (colSums(matrix_readcount_use[
stringr::str_detect(
string = stringr::str_remove(
string = rownames(matrix_readcount_use),
pattern = "^E.+_"
),
pattern = "mt-"
),
]) / colSums(matrix_readcount_use))[embedding$cell],
label = glue::glue("{EMBEDDING_TITLE_PREFIX}; MT %"),
color_legend = TRUE,
sort_values = TRUE,
shuffle_values = FALSE
) + theme_customized_embedding() +
geom_segment_layerlist(
p_embedding_backbone,
p_embedding_pseudotime,
p_embedding_UMI,
p_embedding_MT
) |>
purrr::reduce(`+`) +
patchwork::plot_layout(ncol = 2, byrow = TRUE) +
patchwork::plot_annotation(
theme = ggplot2::theme(plot.margin = ggplot2::margin())
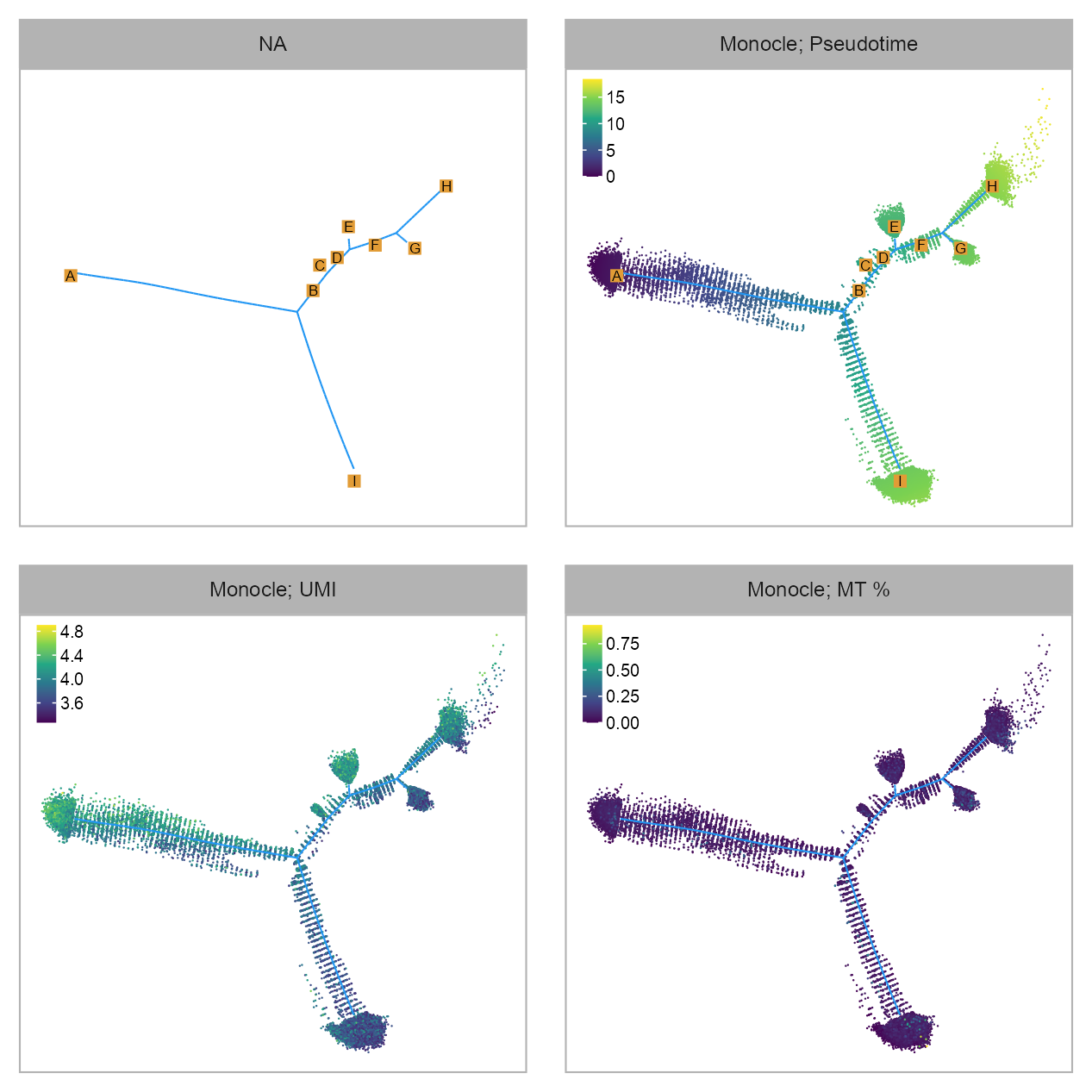
)
embedding |>
dplyr::mutate(
num_umis = Matrix::colSums(matrix_readcount_use[, cell]),
num_features = Matrix::colSums(matrix_readcount_use[, cell] > 0),
) |>
dplyr::group_by(state) |>
dplyr::summarise(
num_cells = n(),
median_umis = median(num_umis),
median_features = median(num_features)
) |>
dplyr::mutate(
state = LETTERS[as.integer(state)]
) |>
gt::gt() |>
gt::data_color(
columns = c(median_umis),
fn = scales::col_numeric(
palette = c(
"green", "orange", "red"
),
domain = NULL
)
) |>
gt::fmt_number(
columns = c(num_cells),
sep_mark = ",",
decimals = 0
) |>
gt::fmt_number(
columns = c(median_umis, median_features),
sep_mark = ",",
decimals = 1
) |>
gt::grand_summary_rows(
columns = c(state),
fns = list(
Count = ~ n()
),
fmt = ~ gt::fmt_number(., decimals = 0, use_seps = TRUE)
) |>
gt::grand_summary_rows(
columns = c(median_umis:median_features),
fns = list(
Mean = ~ mean(.)
),
fmt = ~ gt::fmt_number(., decimals = 1, use_seps = TRUE)
) |>
gt::grand_summary_rows(
columns = c("num_cells"),
fns = list(
Sum = ~ sum(.)
),
fmt = ~ gt::fmt_number(., decimals = 0, use_seps = TRUE)
) |>
gt::tab_header(
title = gt::md("**Monocle**; Cellular state")
)| Monocle; Cellular state | ||||
| state | num_cells | median_umis | median_features | |
|---|---|---|---|---|
| A | 8,106 | 14,130.0 | 3,644.5 | |
| B | 206 | 8,527.0 | 2,717.5 | |
| C | 538 | 12,166.5 | 3,373.0 | |
| D | 181 | 10,272.0 | 2,977.0 | |
| E | 2,380 | 12,835.5 | 3,579.5 | |
| F | 965 | 7,742.0 | 2,573.0 | |
| G | 1,577 | 5,636.0 | 2,067.0 | |
| H | 4,064 | 10,072.0 | 3,018.5 | |
| I | 4,676 | 4,981.5 | 1,572.0 | |
| Count | 9 | — | — | — |
| Mean | — | — | 9,595.8 | 2,835.8 |
| Sum | — | 22,693 | — | — |
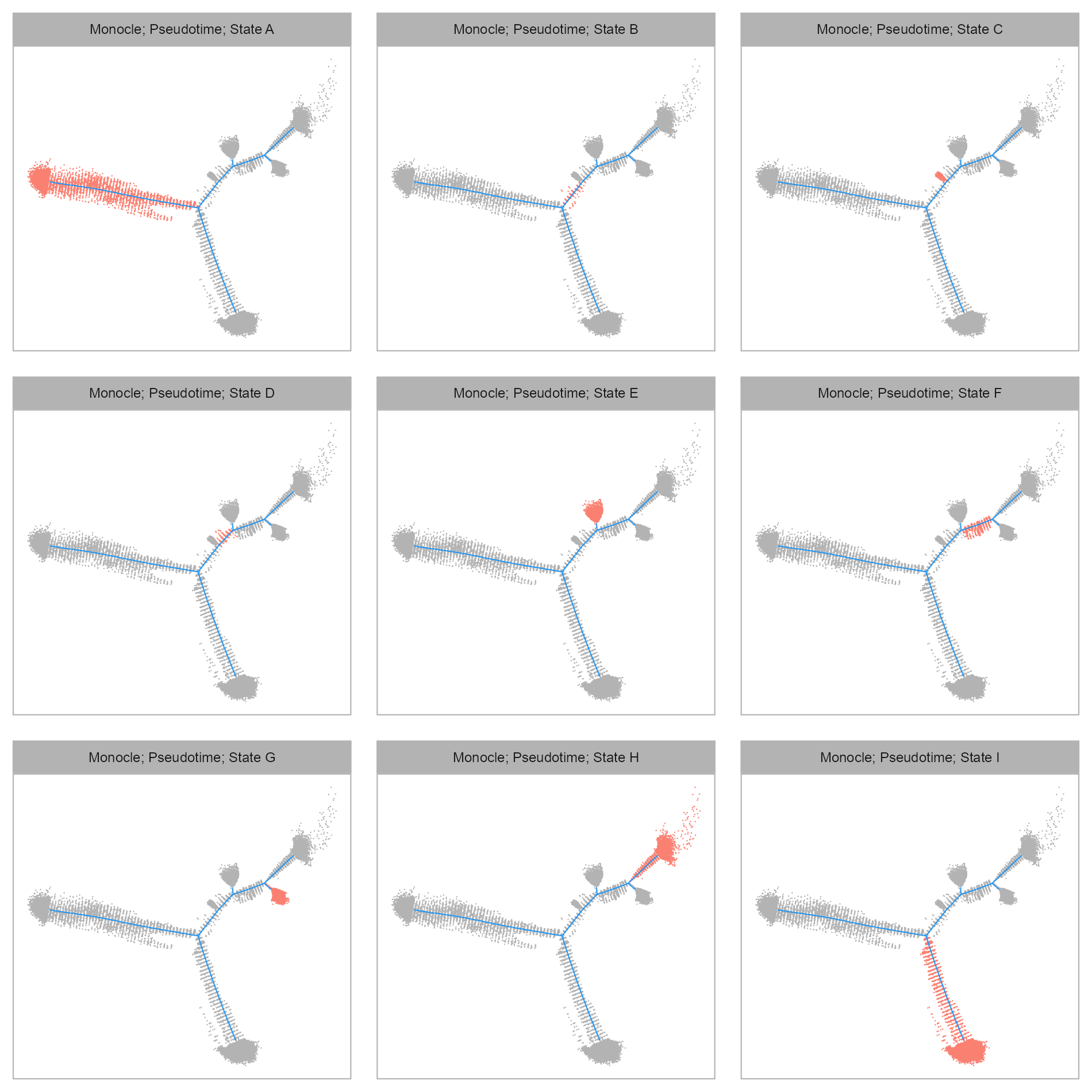
purrr::map(levels(embedding$state), \(x) {
plot_embedding(
data = embedding[, c(x_column, y_column)],
color = as.integer(embedding$state == x) |> as.factor(),
label = glue::glue(
"{EMBEDDING_TITLE_PREFIX}; Pseudotime; ",
"State {LETTERS[as.integer(x)]}"
),
color_legend = FALSE,
sort_values = TRUE
) +
theme_customized_embedding() +
ggplot2::scale_color_manual(values = c("grey70", "salmon")) +
geom_segment_layer
}) |>
purrr::reduce(`+`) +
patchwork::plot_layout(ncol = 3, byrow = TRUE) +
patchwork::plot_annotation(
theme = ggplot2::theme(plot.margin = ggplot2::margin())
)
embedding |>
dplyr::mutate(
num_umis = Matrix::colSums(matrix_readcount_use[, cell]),
num_features = Matrix::colSums(matrix_readcount_use[, cell] > 0),
) |>
dplyr::group_by(group) |>
dplyr::summarise(
num_cells = n(),
median_umis = median(num_umis),
median_features = median(num_features)
) |>
dplyr::select(
group, dplyr::everything()
) |>
gt::gt() |>
gt::fmt_number(
columns = c(num_cells),
sep_mark = ",",
decimals = 0
) |>
gt::fmt_number(
columns = c(median_umis, median_features),
sep_mark = ",",
decimals = 1
) |>
gt::data_color(
columns = c(group),
fn = scales::col_factor(
palette = paletteer::paletteer_d(
n = 5, palette = "colorblindr::OkabeIto"
) |> as.character(),
domain = NULL
)
) |>
gt::data_color(
columns = c(median_umis),
fn = scales::col_numeric(
palette = c(
"green", "orange", "red"
),
domain = NULL
)
) |>
gt::grand_summary_rows(
columns = c(num_cells),
fns = list(
Count = ~ n()
),
fmt = ~ gt::fmt_number(., decimals = 0, use_seps = TRUE)
) |>
gt::grand_summary_rows(
columns = c(median_umis:median_features),
fns = list(
Mean = ~ mean(.)
),
fmt = ~ gt::fmt_number(., decimals = 1, use_seps = TRUE)
) |>
gt::grand_summary_rows(
columns = c(num_cells),
fns = list(
Sum = ~ sum(.)
),
fmt = ~ gt::fmt_number(., decimals = 0, use_seps = TRUE)
) |>
gt::tab_header(
title = gt::md("**Monocle**; Group")
) |>
gt::tab_options(
table.width = gt::pct(50)
)| Monocle; Group | ||||
| group | num_cells | median_umis | median_features | |
|---|---|---|---|---|
| Primary | 64 | 6,244.5 | 2,619.5 | |
| Uninfected | 4,914 | 13,713.0 | 3,571.0 | |
| 10F, D7 | 5,291 | 10,534.0 | 3,043.0 | |
| 10F, D14 | 5,639 | 9,724.0 | 2,881.0 | |
| 3F, D7 | 6,785 | 8,805.0 | 2,812.0 | |
| Count | — | 5 | — | — |
| Mean | — | — | 9,804.1 | 2,985.3 |
| Sum | — | 22,693 | — | — |
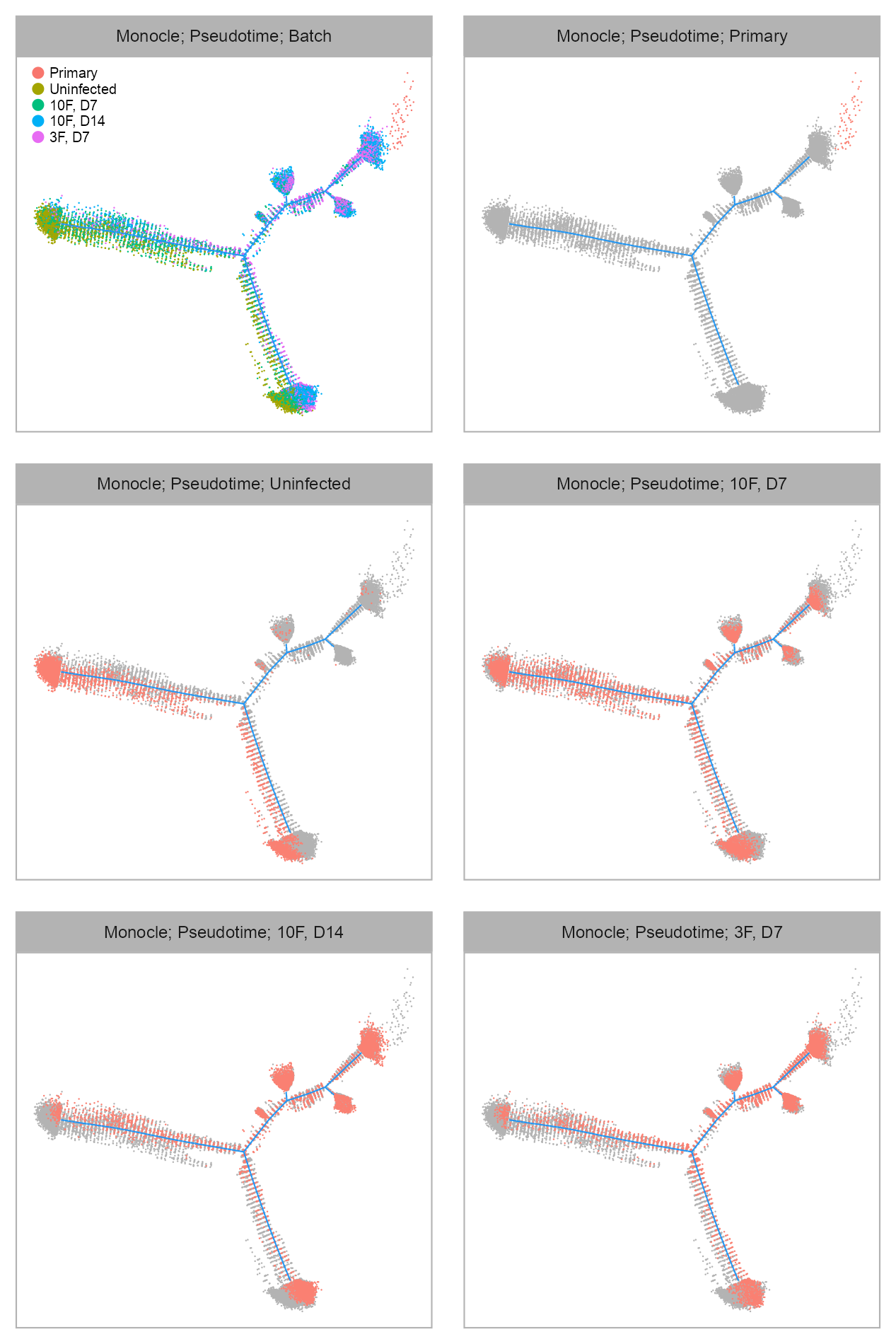
list(
plot_embedding(
data = embedding[, c(x_column, y_column)],
color = embedding$group,
label = glue::glue("{EMBEDDING_TITLE_PREFIX}; Pseudotime; Batch"),
color_legend = TRUE,
sort_values = FALSE,
shuffle_values = TRUE
) +
theme_customized_embedding() +
geom_segment_layer,
purrr::map(levels(embedding$group), \(x) {
plot_embedding(
data = embedding[, c(x_column, y_column)],
color = as.integer(embedding$group == x) |> as.factor(),
label = glue::glue("{EMBEDDING_TITLE_PREFIX}; Pseudotime; {x}"),
color_legend = FALSE,
sort_values = TRUE
) +
theme_customized_embedding() +
ggplot2::scale_color_manual(values = c("grey70", "salmon")) +
geom_segment_layer
})
) |>
purrr::reduce(`+`) +
patchwork::plot_layout(ncol = 2, byrow = TRUE) +
patchwork::plot_annotation(
theme = ggplot2::theme(plot.margin = ggplot2::margin())
)
color_palette <- setNames(
object = c("#e37b3e", "#44b29c", "#de5a49", "#f7a8a5", "#f0ca4e"),
nm = c("Primary", "3F, D7", "10F, D14", "10F, D7", "Uninfected")
)
scales::show_col(color_palette, borders = NA)
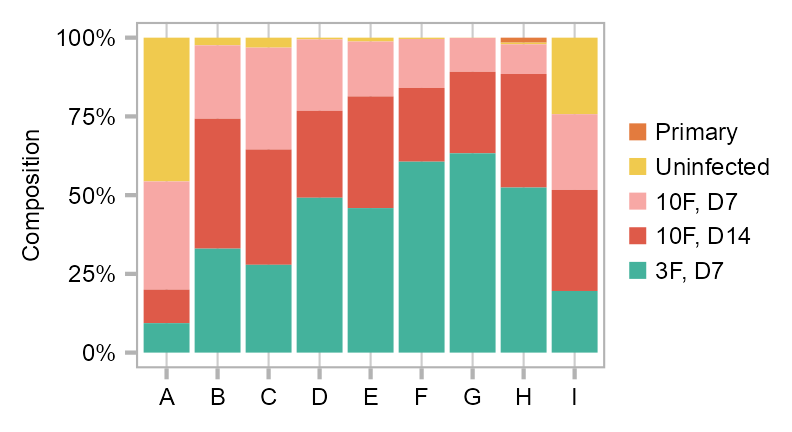
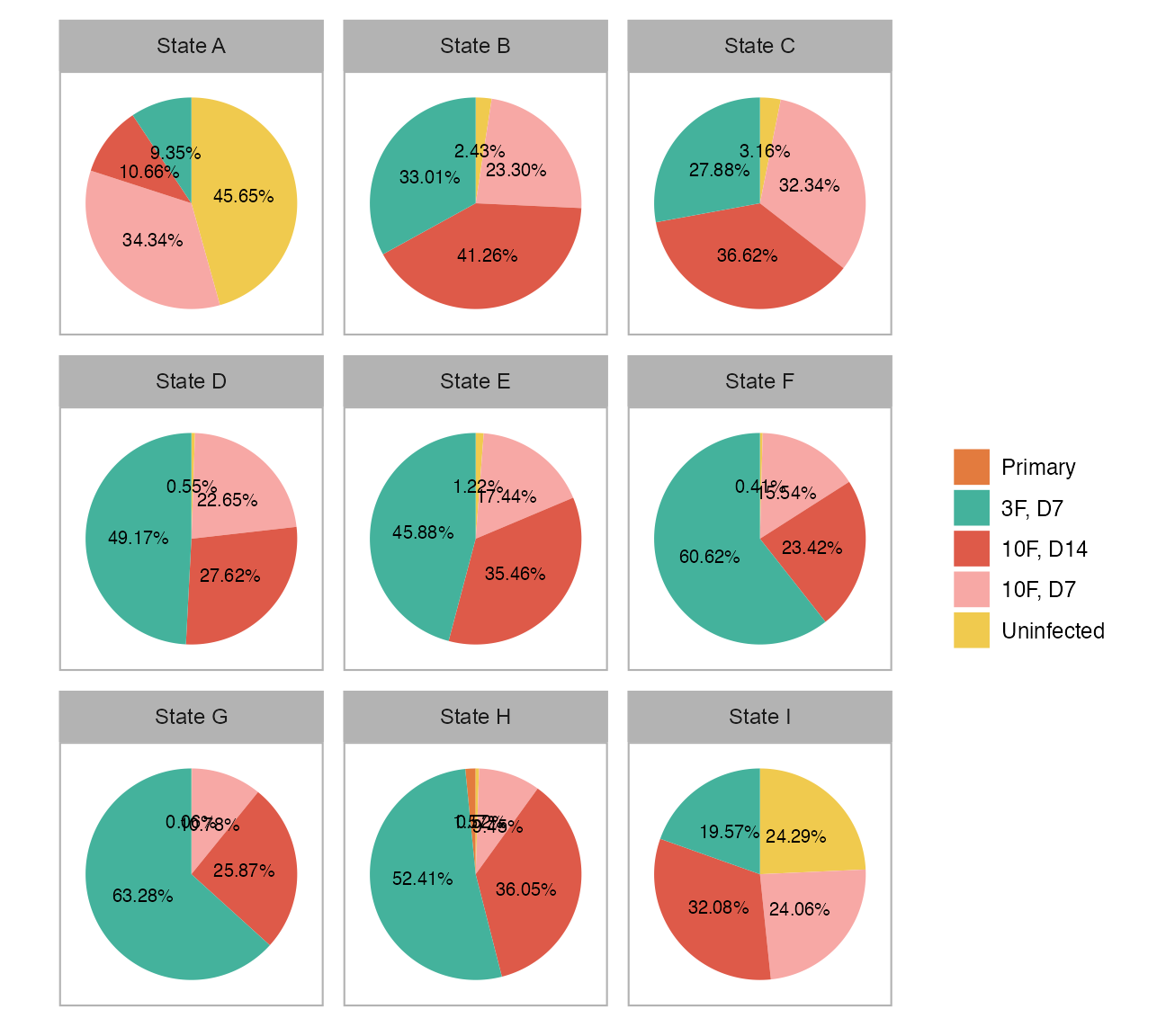
calc_group_composition(
data = embedding,
x = "state",
group = "group"
) |>
dplyr::mutate(
state = factor(
LETTERS[as.integer(state)]
)
) |>
plot_barplot(
x = "state",
y = "percentage",
z = "group",
legend_ncol = 1
) +
ggplot2::scale_fill_manual(
values = color_palette
)
calc_group_composition(
data = embedding,
x = "state",
group = "group"
) |>
dplyr::mutate(
group = factor(
group,
levels = c("Primary", "3F, D7", "10F, D14", "10F, D7", "Uninfected")
)
) |>
split(~state) |>
purrr::map(
\(x) {
x |>
dplyr::mutate(
label_position = cumsum(percentage) - percentage / 2
)
}
) |>
dplyr::bind_rows() |>
{
\(x) {
ggplot2::ggplot(
data = x,
aes(
x = "",
y = percentage,
fill = group
)
) +
geom_bar(width = 1, stat = "identity") +
coord_polar("y", start = 0) +
facet_wrap(
~state,
labeller = labeller(
state = setNames(
object = paste(
"State",
LETTERS[as.integer(levels(embedding$state))]
),
nm = levels(embedding$state)
)
)
) +
ggplot2::geom_text(
data = x,
ggplot2::aes(
y = label_position,
label = scales::percent(percentage, accuracy = 0.01)
), size = 5 / ggplot2::.pt
) +
ggplot2::scale_x_discrete(name = NULL) +
ggplot2::scale_y_continuous(name = NULL) +
ggplot2::scale_fill_manual(
name = NULL,
values = color_palette
) +
theme_customized_violin() %+replace%
ggplot2::theme(
axis.text.x = ggplot2::element_blank(),
axis.ticks = ggplot2::element_blank(),
legend.text = ggplot2::element_text(
size = 6,
margin = ggplot2::margin(
t = 0, r = 0,
b = 0, l = -1,
unit = "mm"
)
),
legend.key.size = ggplot2::unit(4, "mm")
)
}
}()
FEATURES_SELECTED <- c(
"ENSMUSG00000016458_Wt1",
"ENSMUSG00000025105_Bnc1",
"ENSMUSG00000036098_Myrf",
"ENSMUSG00000042985_Upk3b"
)
purrr::map(FEATURES_SELECTED, \(x) {
selected_feature <- x
cat(selected_feature, "\n")
values <- log10(
calc_cpm(matrix_readcount_use[, embedding$cell])
[selected_feature, ] + 1
)
values[embedding$group != "3F, D7"] <- NA
plot_embedding(
data = embedding[, c(x_column, y_column)],
color = values,
label = glue::glue(
"{EMBEDDING_TITLE_PREFIX}; 3F, D7; ",
"{x |> stringr::str_remove(pattern = \"^E.+_\")}"
),
color_legend = TRUE,
sort_values = TRUE,
na_value = "grey70"
) +
theme_customized_embedding() +
geom_segment_layer
}) |>
# unlist(recursive = FALSE) |>
purrr::reduce(`+`) +
patchwork::plot_layout(ncol = 2, byrow = FALSE) +
patchwork::plot_annotation(
theme = ggplot2::theme(plot.margin = ggplot2::margin())
)ENSMUSG00000016458_Wt1
ENSMUSG00000025105_Bnc1
ENSMUSG00000036098_Myrf
ENSMUSG00000042985_Upk3b 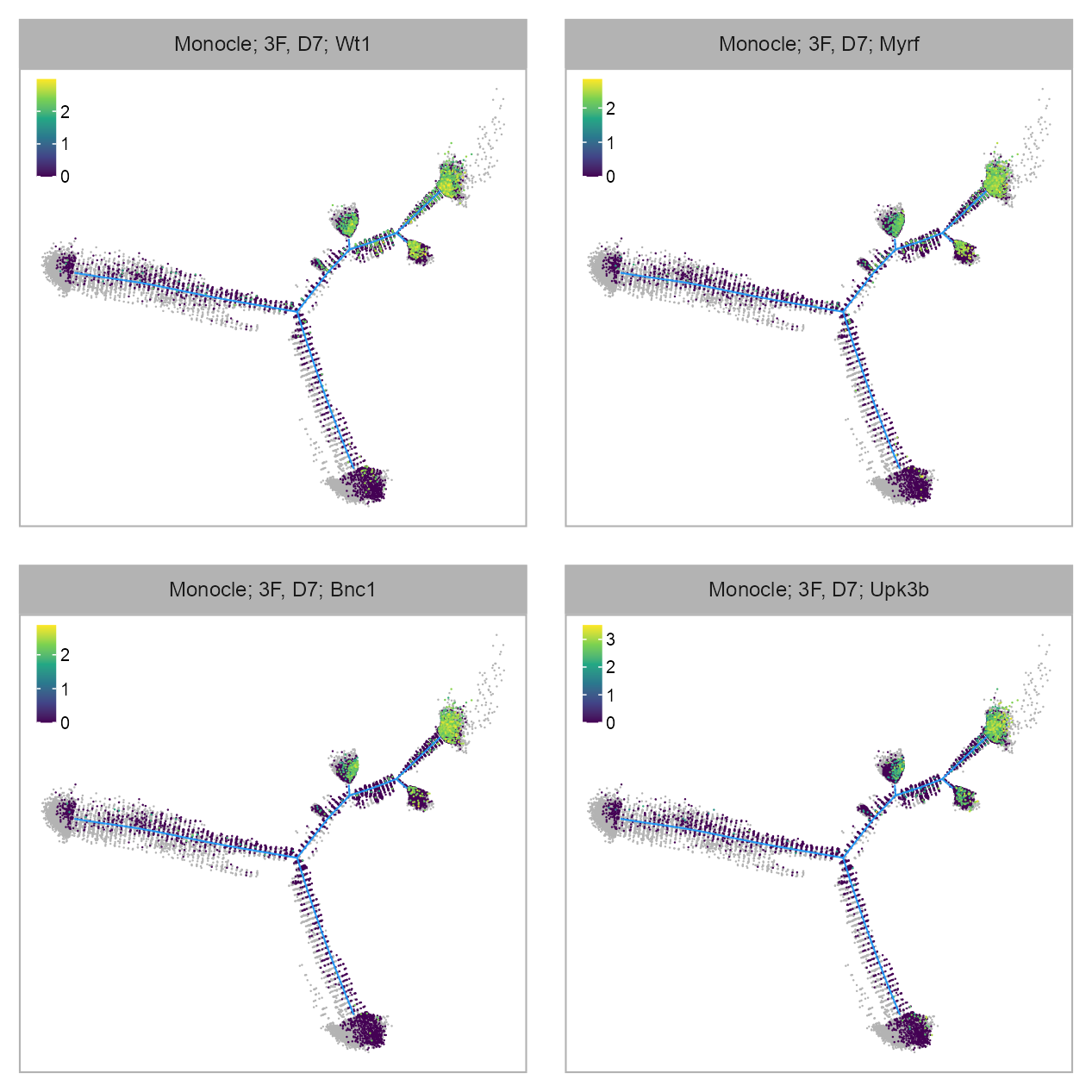
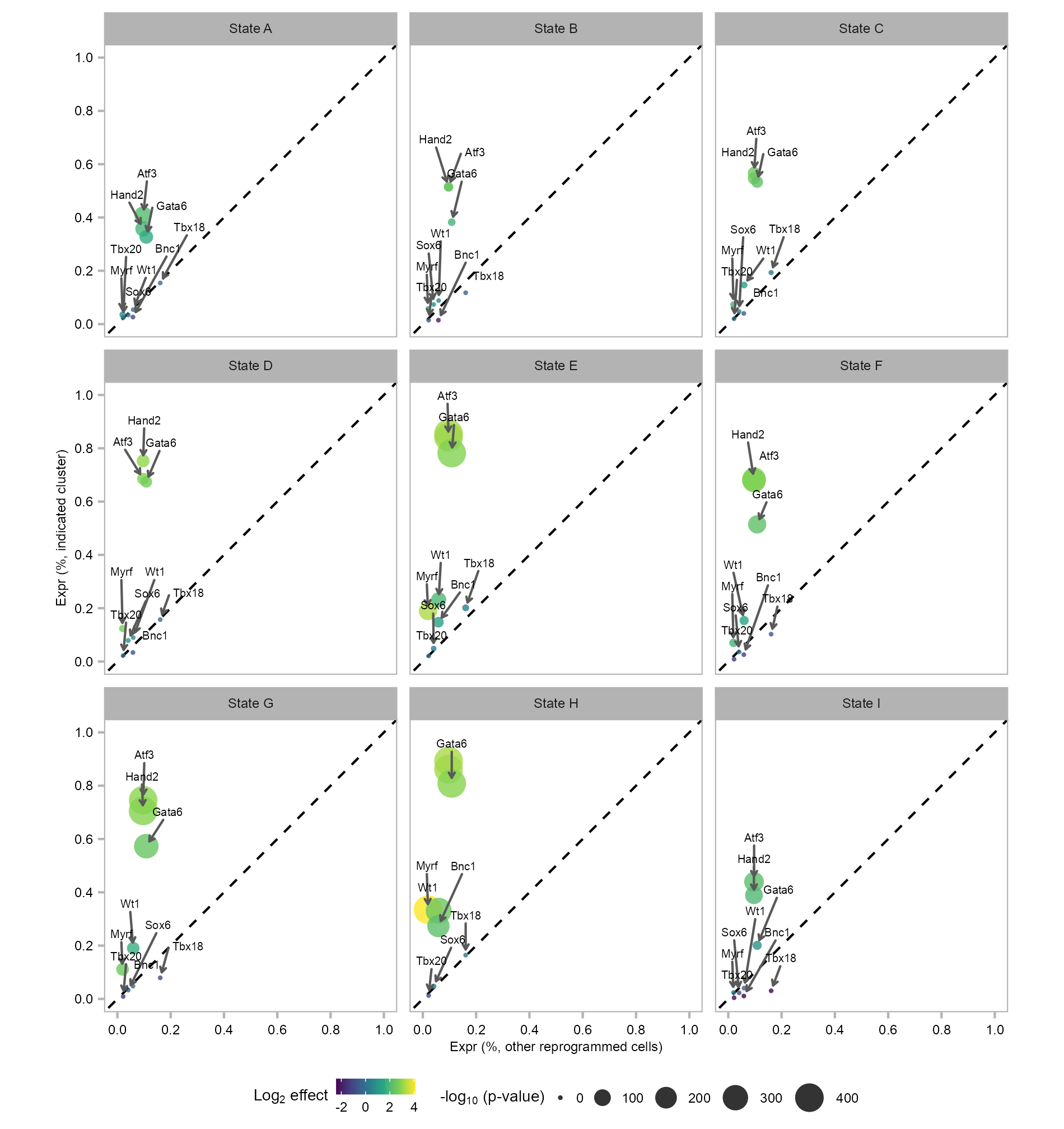
features_selected_10 <- c(
"ENSMUSG00000026628_Atf3",
"ENSMUSG00000016458_Wt1",
"ENSMUSG00000025105_Bnc1",
"ENSMUSG00000051910_Sox6",
"ENSMUSG00000045680_Tcf21",
"ENSMUSG00000038193_Hand2",
"ENSMUSG00000031965_Tbx20",
"ENSMUSG00000032419_Tbx18",
"ENSMUSG00000005836_Gata6",
"ENSMUSG00000036098_Myrf"
)states_selected <- levels(embedding$state)
enriched_factors <- do.call(
rbind.data.frame,
lapply(states_selected, \(x) {
cells_1 <- embedding$cell[
embedding$state == x & embedding$category == "BL19"
]
cells_2 <- embedding$cell[embedding$category == "BL7"]
cat(x, length(cells_1), length(cells_2), "\n")
de_paired <- detect_de(
cell_group_a = cells_1,
cell_group_b = cells_2,
matrix_readcount = matrix_readcount_use,
matrix_cpm = calc_cpm(matrix_readcount_use),
only_enrichment = TRUE
) |>
dplyr::mutate(category = x) |>
tibble::rownames_to_column(var = "feature") |>
dplyr::filter(feature %in% features_selected_10)
})
) |>
dplyr::filter(category %in% states_selected) |>
dplyr::mutate(
category = factor(category,
levels = states_selected
),
symbol = stringr::str_remove(
string = feature,
pattern = "^.+_"
)
)1 758 4914
2 68 4914
3 150 4914
4 89 4914
5 1092 4914
6 585 4914
7 998 4914
8 2130 4914
9 915 4914 enriched_factors <- enriched_factors |>
dplyr::mutate(
pval_adj_log = ifelse(-log10(pval_adj) == Inf, 400, -log10(pval_adj))
)
ggplot2::ggplot() +
ggplot2::geom_abline(intercept = 0, slope = 1, linetype = 2) +
ggplot2::geom_point(
data = enriched_factors,
ggplot2::aes(positive_frac_b,
positive_frac_a,
size = pval_adj_log, # -log10(pval_adj),
color = log2_effect
),
alpha = .8,
stroke = 0, shape = 16
) +
ggplot2::facet_wrap(
~category,
ncol = 3,
labeller = ggplot2::labeller(
category = setNames(
object = paste("State", LETTERS[as.integer(states_selected)]),
nm = states_selected
)
)
) +
ggplot2::coord_fixed() +
ggplot2::scale_color_viridis_c(
name = expression(paste("Log"[2], " effect"))
) +
ggplot2::scale_size_continuous(
name = expression(paste("-log"[10], " (p-value)"))
) +
ggplot2::guides(
color = ggplot2::guide_colorbar(order = 1),
size = ggplot2::guide_legend(order = 2)
) +
ggplot2::scale_x_continuous(
name = "Expr (%, other reprogrammed cells)",
limits = c(0, 1), breaks = seq(0, 1, .2)
) +
ggplot2::scale_y_continuous(
name = "Expr (%, indicated cluster)",
limits = c(0, 1), breaks = seq(0, 1, .2)
) +
theme_customized_violin() %+replace%
ggplot2::theme(
legend.background = ggplot2::element_blank(),
legend.margin = ggplot2::margin(t = 0, r = 0, b = 0, l = 0, unit = "mm"),
legend.key.size = ggplot2::unit(2.5, "mm"),
legend.text = ggplot2::element_text(family = "Arial", size = 6),
legend.title = ggplot2::element_text(family = "Arial", size = 7),
legend.position = "bottom",
legend.box = "horizontal",
legend.box.background = ggplot2::element_blank()
) +
ggrepel::geom_text_repel(
data = enriched_factors,
ggplot2::aes(
positive_frac_b,
positive_frac_a,
label = symbol
),
#
size = 5 / ggplot2::.pt,
family = "Arial",
box.padding = .2,
point.padding = .2,
nudge_y = .15,
arrow = ggplot2::arrow(length = ggplot2::unit(.02, "npc")),
segment.color = "grey35",
color = "black"
)
make_groups <- function(x, number_of_members) {
y <- seq_along(x)
chunks <- split(x, ceiling(y / number_of_members))
if (length(chunks[[length(chunks)]]) < number_of_members) {
chunks[[length(chunks) - 1]] <- c(
chunks[[length(chunks) - 1]], chunks[[length(chunks)]]
)
chunks[[length(chunks)]] <- NULL
}
return(chunks)
}monocle_states_selected <- c(
1, 2, 4, 6, 8
)
cells_selected_reprogrammed <- embedding |>
dplyr::filter(
state %in% monocle_states_selected,
!category %in% c(
"BL5",
"BL6",
"BL7"
)
) |>
dplyr::arrange(pseudotime) |>
dplyr::pull(cell)
cells_selected_reference <- embedding |>
dplyr::filter(
state %in% monocle_states_selected,
category %in% c("BL5", "BL6")
) |>
dplyr::arrange(pseudotime) |>
dplyr::pull(cell)
Map(length, list(cells_selected_reprogrammed, cells_selected_reference)) |>
unlist()[1] 9727 64NUM_CELLS_TO_MERGE <- 20
matrix_heatmap_reprogrammed <- purrr::map(
make_groups(cells_selected_reprogrammed, NUM_CELLS_TO_MERGE), \(x) {
Matrix::rowSums(matrix_readcount_use[, x])
}
) |>
purrr::reduce(cbind) |>
calc_cpm()
colnames(matrix_heatmap_reprogrammed) <- paste(
"metacell_reprogrammed",
1:ncol(matrix_heatmap_reprogrammed),
sep = "_"
)matrix_heatmap_reference <- purrr::map(
make_groups(cells_selected_reference, NUM_CELLS_TO_MERGE), \(x) {
Matrix::rowSums(matrix_readcount_use[, x])
}
) |>
purrr::reduce(cbind) |>
calc_cpm()
matrix_heatmap_reference <- purrr::map(
make_groups(cells_selected_reference, NUM_CELLS_TO_MERGE), \(x) {
Matrix::rowMeans(calc_cpm(matrix_readcount_use[, x]))
}
) |>
purrr::reduce(cbind)
colnames(matrix_heatmap_reference) <- paste(
"metacell_reference",
1:ncol(matrix_heatmap_reference),
sep = "_"
)matrix_kmeans <- log10(
matrix_heatmap_reprogrammed[features_selected_heatmap, ] + 1
)
pos_frac <- .2
features_selected_heatmap <- features_selected_heatmap[
rowMeans(matrix_kmeans > 0) >= pos_frac
]
matrix_kmeans <- matrix_kmeans[features_selected_heatmap, ]
matrix_kmeans <- t(scale(t(matrix_kmeans)))
kmeans_limits <- quantile(matrix_kmeans, c(0.05, 0.95))
matrix_kmeans[matrix_kmeans < kmeans_limits[1]] <- kmeans_limits[1]
matrix_kmeans[matrix_kmeans > kmeans_limits[2]] <- kmeans_limits[2]
NUM_CENTERS <- 6
SEED <- 20180706
set.seed(SEED)
kmeans_out <- kmeans(
matrix_kmeans,
NUM_CENTERS,
iter.max = 10,
nstart = 20
)# customize numbers of features per group
num_features_per_group <- kmeans_out$cluster |>
table() |>
tibble::enframe() |>
dplyr::rename(cluster = name, count = value) |>
mutate(
x = quantile(seq_len(dim(kmeans_out$centers)[2]), .5),
# y = 1,
y = 0.7,
label = paste("n =", count)
) |>
dplyr::mutate(
group = dplyr::case_when(
cluster == 6 ~ "Signature 1",
cluster == 1 ~ "Signature 2",
cluster == 3 ~ "Signature 3",
cluster == 5 ~ "Signature 4",
cluster == 2 ~ "Signature 5",
cluster == 4 ~ "Signature 6"
),
group = factor(group)
)
# customize x axis limits
x_breaks <- quantile(seq_len(dim(kmeans_out$centers)[2]), probs = seq(0, 1, 1))
# draw
p_kmeans <- kmeans_out$centers |>
t() |>
as.data.frame() |>
tibble::rownames_to_column(var = "metacell") |>
dplyr::mutate(x = 1:n()) |>
tidyr::pivot_longer(
-c("metacell", "x"),
names_to = "cluster",
values_to = "value"
) |>
dplyr::mutate(
group = dplyr::case_when(
cluster == 6 ~ "Signature 1",
cluster == 1 ~ "Signature 2",
cluster == 3 ~ "Signature 3",
cluster == 5 ~ "Signature 4",
cluster == 2 ~ "Signature 5",
cluster == 4 ~ "Signature 6"
),
group = factor(group)
) |>
ggplot2::ggplot(ggplot2::aes(x, value)) +
ggplot2::geom_line(size = .2) +
ggplot2::facet_wrap(
~group,
# scales = "free_y",
ncol = 3,
# strip.position = "left",
strip.position = "top",
# labeller = labeller(cluster = facet_labels)
) +
ggplot2::scale_x_continuous(
name = glue::glue(
"Scaled pseudotime (state ",
paste(LETTERS[as.integer(monocle_states_selected)],
collapse = ""
),
")"
),
breaks = x_breaks
) +
ggplot2::scale_y_continuous(
name = "Scaled expr (Z score)",
limits = c(-1.5, 1.5)
) +
ggplot2::geom_text(
data = num_features_per_group,
ggplot2::aes(x, y, label = label),
family = "Arial",
vjust = -.5,
size = 2
) +
ggplot2::labs(title = "Reprogrammed cells") +
theme_customized_violin(
panel_border_color = "black",
strip_background_fill = "grey80"
) %+replace%
ggplot2::theme(
axis.text.x = ggplot2::element_text(
family = "Arial",
angle = 90,
vjust = .5,
hjust = 1,
size = 6
),
plot.title = ggplot2::element_text(
family = "Arial",
size = 6,
# margin = margin(t = 0, r = 0, b = 0, l = 0, unit = "mm"))
hjust = .5
)
)g <- ggplot2::ggplot_gtable(ggplot2::ggplot_build(p_kmeans))
stript <- which(grepl("strip-t", g$layout$name))
colors_strip_background_fill <- ggthemes::tableau_color_pal(
"Tableau 10"
)(n = NUM_CENTERS)
colors_strip_background_fill <- c(
colors_strip_background_fill[4:6],
colors_strip_background_fill[1:3]
)
k <- 1
for (i in stript) {
j <- which(grepl("rect", g$grobs[[i]]$grobs[[1]]$childrenOrder))
g$grobs[[i]]$grobs[[1]]$children[[j]]$gp$fill <-
colors_strip_background_fill[k]
k <- k + 1
}
grid::grid.draw(g)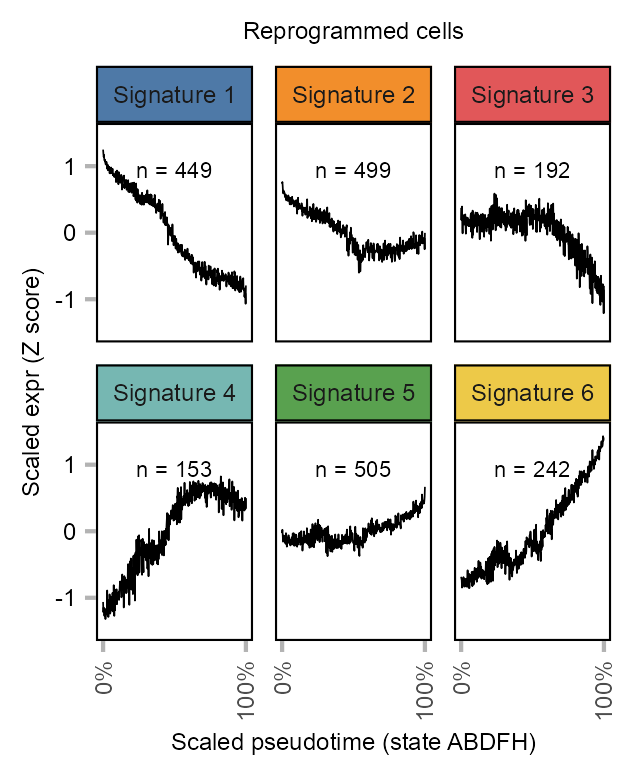
feature_clusters <- c(6, 1, 3, 5, 2, 4)
features_selected_heatmap <- purrr::map(feature_clusters, \(x) {
names(kmeans_out$cluster)[kmeans_out$cluster == x]
}) |>
unlist()
features_selected_heatmap <- paste(
features_selected_heatmap, gene_symbols[features_selected_heatmap],
sep = "_"
)
# begin
matrix_heatmap <- cbind(
matrix_heatmap_reprogrammed,
matrix_heatmap_reference
)
matrix_heatmap <- matrix_heatmap[features_selected_heatmap, ]
matrix_heatmap <- matrix_heatmap[rowSums(matrix_heatmap) != 0, ]
matrix_heatmap <- log10(matrix_heatmap + 1)
matrix_heatmap <- t(scale(t(matrix_heatmap)))
heatmap_limits <- quantile(matrix_heatmap, c(0.05, 0.95))
matrix_heatmap[matrix_heatmap < heatmap_limits[1]] <- heatmap_limits[1]
matrix_heatmap[matrix_heatmap > heatmap_limits[2]] <- heatmap_limits[2]# get metacell states
metacell_annotation_reprogrammed <- purrr::map_int(
make_groups(cells_selected_reprogrammed, NUM_CELLS_TO_MERGE), \(x) {
x |>
as.data.frame() |>
`colnames<-`("cell") |>
dplyr::left_join(
embedding |>
dplyr::select(cell, state),
by = "cell"
) |>
dplyr::count(state) |>
dplyr::slice(1) |>
dplyr::pull(state)
}
)
# create labels for metacells
anno_labels_tbl_state_reprogrammed <- table(metacell_annotation_reprogrammed) |>
tibble::enframe(name = "group") |>
dplyr::mutate(
cum_sum = cumsum(value),
position = cum_sum - value / 2
)
anno_labels_state_reprogrammed <- rep(NA, ncol(matrix_heatmap_reprogrammed))
for (i in seq_len(nrow(anno_labels_tbl_state_reprogrammed))) {
anno_labels_state_reprogrammed[
anno_labels_tbl_state_reprogrammed[i, "position", drop = TRUE] # - 5
] <- LETTERS[
as.integer(anno_labels_tbl_state_reprogrammed[i, "group", drop = TRUE])
]
}# create heatmap column annotation
ha_column_reprogrammed <- ComplexHeatmap::HeatmapAnnotation(
#
state = ComplexHeatmap::anno_simple(
metacell_annotation_reprogrammed,
pch = anno_labels_state_reprogrammed,
col = setNames(
object = scales::hue_pal()(
n = length(unique(monocle2_result[[1]]$state))
),
nm = sort(unique(monocle2_result[[1]]$state))
),
which = "column",
pt_size = unit(5 / ggplot2::.pt, "mm"),
pt_gp = grid::gpar(
fontfamily = "Arial",
fontsize = 5
),
simple_anno_size = unit(1.5, "mm")
),
#
show_annotation_name = TRUE,
annotation_label = c(
"State"
),
annotation_name_gp = grid::gpar(fontfamily = "Arial", fontsize = 5),
annotation_name_side = "left"
)
# create heatmap row annotation; left
ha_left <- ComplexHeatmap::HeatmapAnnotation(
lineage = ComplexHeatmap::anno_simple(
setNames(
object = rep(
seq_len(NUM_CENTERS),
purrr::map_int(feature_clusters, \(x) {
sum(kmeans_out$cluster == x)
})
),
nm = features_selected_heatmap
),
col = setNames(
object = ggthemes::tableau_color_pal("Tableau 10")(n = NUM_CENTERS),
nm = seq_len(NUM_CENTERS)
),
which = "row",
pt_gp = grid::gpar(
fontfamily = "Arial",
fontsize = 5
),
simple_anno_size = unit(1.5, "mm")
),
which = "row",
show_annotation_name = FALSE,
annotation_label = c(
"Cluster"
),
annotation_name_gp = grid::gpar(fontfamily = "Arial", fontsize = 5)
)# map color
col_fun <- circlize::colorRamp2(
quantile(
c(
min(matrix_heatmap),
max(matrix_heatmap)
),
seq(0, 1, 0.1)
),
# viridis::plasma(11)
wesanderson::wes_palette("Zissou1", 11, type = "continuous")
)
RASTERISED <- FALSE
# create heatmap
ht_reprogrammed <- ComplexHeatmap::Heatmap(
matrix = matrix_heatmap[, colnames(matrix_heatmap_reprogrammed)] |>
as.matrix(),
rect_gp = grid::gpar(col = NA, lwd = 0),
col = col_fun,
#
row_title_gp = grid::gpar(fontfamily = "Arial", fontsize = 6),
row_title_rot = 0,
column_title_gp = grid::gpar(fontfamily = "Arial", fontsize = 6),
column_title_rot = 0,
#
cluster_rows = FALSE,
show_row_dend = FALSE,
cluster_columns = FALSE,
show_column_dend = FALSE,
#
show_row_names = FALSE,
show_column_names = FALSE,
#
top_annotation = ha_column_reprogrammed,
bottom_annotation = NULL,
left_annotation = ha_left,
right_annotation = NULL,
#
column_split = factor(
rep("Reprogrammed", length(metacell_annotation_reprogrammed))
),
column_gap = unit(0, "mm"),
#
show_heatmap_legend = FALSE,
heatmap_legend_param = list(
title = "Expr",
title_gp = grid::gpar(
fontfamily = "Arial",
fontsize = 6
),
legend_direction = "vertical",
labels_gp = grid::gpar(
fontfamily = "Arial",
fontsize = 5
),
legend_height = unit(15, "mm"),
legend_width = unit(5, "mm")
),
#
use_raster = RASTERISED
)metacell_annotation_reference <- rep(
x = "Target",
times = ncol(matrix_heatmap_reference)
)
ha_column_reference <- ComplexHeatmap::HeatmapAnnotation(
#
state = ComplexHeatmap::anno_simple(
metacell_annotation_reference,
# pch = anno_labels_state_reprogrammed,
col = setNames(
object = "#ed7899",
nm = "Target"
),
which = "column",
pt_size = unit(2, "mm"),
pt_gp = grid::gpar(
fontfamily = "Arial",
fontsize = 5
),
simple_anno_size = unit(1.5, "mm")
),
#
show_annotation_name = FALSE,
annotation_label = c(
"State"
),
annotation_name_gp = grid::gpar(fontfamily = "Arial", fontsize = 5),
annotation_name_side = "left"
)features_selected_to_mark_right <- c(
features_selected_10,
"ENSMUSG00000015627_Gata5",
"ENSMUSG00000031517_Gpm6a"
)
features_selected_to_mark_right <- features_selected_to_mark_right[
features_selected_to_mark_right %in% rownames(matrix_heatmap)
]
features_selected_to_mark_right_idx <- which(
rownames(matrix_heatmap) %in% features_selected_to_mark_right
)
features_selected_to_mark_right_labels <- rownames(matrix_heatmap)[
features_selected_to_mark_right_idx
] |>
stringr::str_remove(
pattern = "^E.+_"
)
ha_right <- ComplexHeatmap::rowAnnotation(
foo = ComplexHeatmap::anno_mark(
at = features_selected_to_mark_right_idx,
labels = features_selected_to_mark_right_labels,
which = "row",
side = "right",
lines_gp = grid::gpar(col = "grey50"),
labels_gp = grid::gpar(
fontfamily = "Arial",
fontsize = 5
)
)
)ht_reference <- ComplexHeatmap::Heatmap(
matrix = matrix_heatmap[, colnames(matrix_heatmap_reference)] |> as.matrix(),
rect_gp = grid::gpar(col = NA, lwd = 0),
col = col_fun,
#
row_title_gp = grid::gpar(fontfamily = "Arial", fontsize = 6),
row_title_rot = 0,
column_title_gp = grid::gpar(fontfamily = "Arial", fontsize = 6),
column_title_rot = 0,
#
cluster_rows = FALSE,
show_row_dend = FALSE,
cluster_columns = FALSE,
show_column_dend = FALSE,
#
show_row_names = FALSE,
show_column_names = FALSE,
#
top_annotation = ha_column_reference,
bottom_annotation = NULL,
right_annotation = ha_right,
#
column_split = factor(
rep("Epicardial", length(metacell_annotation_reference))
),
column_gap = unit(0, "mm"),
#
show_heatmap_legend = FALSE,
heatmap_legend_param = list(
title = "Expr",
title_gp = grid::gpar(
fontfamily = "Arial",
fontsize = 6
),
legend_direction = "vertical",
labels_gp = grid::gpar(
fontfamily = "Arial",
fontsize = 5
),
legend_height = unit(15, "mm"),
legend_width = unit(5, "mm")
),
#
use_raster = RASTERISED
)# legend
lgd_colorbar <- ComplexHeatmap::Legend(
col_fun = col_fun,
title = "Expr",
#
grid_height = unit(1, "mm"),
grid_width = unit(2, "mm"),
legend_height = unit(5, "mm"),
legend_width = unit(2, "mm"),
#
labels_gp = grid::gpar(
fontfamily = "Arial",
fontsize = 5
),
title_gp = grid::gpar(
fontfamily = "Arial",
fontsize = 6
)
)
lgd_signature <- ComplexHeatmap::Legend(
title = "Signature",
labels = seq_len(NUM_CENTERS),
legend_gp = grid::gpar(
fill = setNames(
object = ggthemes::tableau_color_pal("Tableau 10")(n = NUM_CENTERS),
nm = seq_len(NUM_CENTERS)
)
),
#
grid_height = unit(1, "mm"),
grid_width = unit(2.5, "mm"),
#
legend_height = unit(5, "mm"),
legend_width = unit(2, "mm"),
#
labels_gp = grid::gpar(
fontfamily = "Arial",
fontsize = 5
),
title_gp = grid::gpar(
fontfamily = "Arial",
fontsize = 6
)
)
pd <- ComplexHeatmap::packLegend(
lgd_colorbar,
lgd_signature,
direction = "vertical"
)ComplexHeatmap::draw(
ht_reprogrammed + ht_reference,
heatmap_legend_list = list(pd),
#
gap = unit(c(1), "mm")
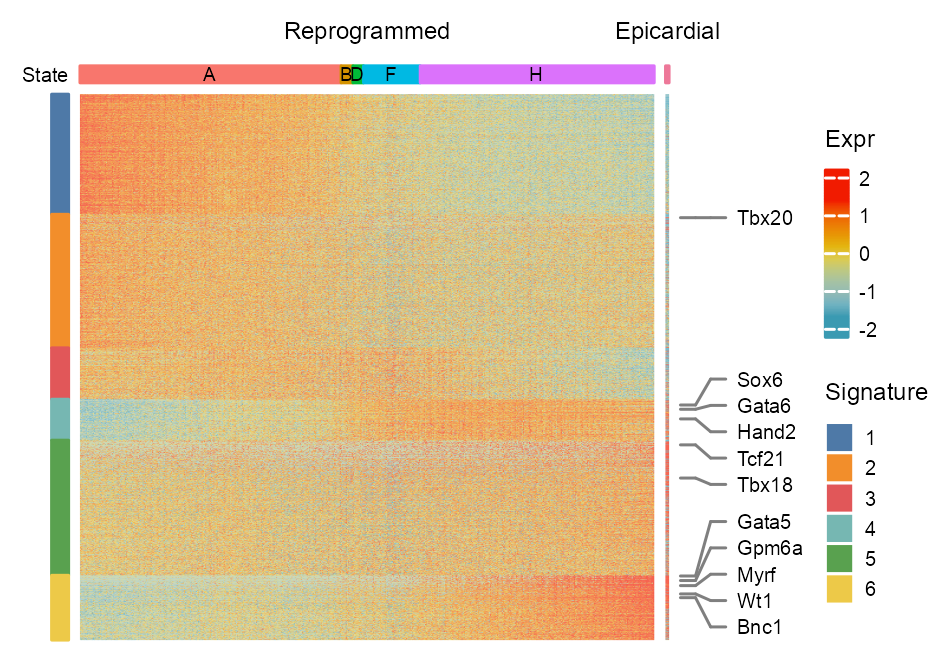
)
devtools::session_info()─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.3.1 (2023-06-16)
os macOS Ventura 13.5
system aarch64, darwin22.4.0
ui unknown
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz America/Chicago
date 2023-08-12
pandoc 2.19.2 @ /Users/jialei/.pyenv/shims/ (via rmarkdown)
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
Biobase 2.60.0 2023-04-25 [1] Bioconductor
BiocGenerics 0.46.0 2023-04-25 [1] Bioconductor
bit 4.0.5 2022-11-15 [1] CRAN (R 4.3.0)
bit64 4.0.5 2020-08-30 [1] CRAN (R 4.3.0)
cachem 1.0.8 2023-05-01 [1] CRAN (R 4.3.0)
callr 3.7.3 2022-11-02 [1] CRAN (R 4.3.0)
circlize 0.4.15 2022-05-10 [1] CRAN (R 4.3.0)
cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)
clue 0.3-64 2023-01-31 [1] CRAN (R 4.3.0)
cluster 2.1.4 2022-08-22 [2] CRAN (R 4.3.1)
codetools 0.2-19 2023-02-01 [2] CRAN (R 4.3.1)
colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.3.0)
combinat 0.0-8 2012-10-29 [1] CRAN (R 4.3.0)
commonmark 1.9.0 2023-03-17 [1] CRAN (R 4.3.0)
ComplexHeatmap 2.16.0 2023-04-25 [1] Bioconductor
crayon 1.5.2 2022-09-29 [1] CRAN (R 4.3.0)
DDRTree 0.1.5 2017-04-30 [1] CRAN (R 4.3.0)
devtools 2.4.5.9000 2023-08-11 [1] Github (r-lib/devtools@163c3f2)
digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.1)
docopt 0.7.1 2020-06-24 [1] CRAN (R 4.3.0)
doParallel 1.0.17 2022-02-07 [1] CRAN (R 4.3.0)
dplyr * 1.1.2.9000 2023-07-19 [1] Github (tidyverse/dplyr@c963d4d)
ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.3.0)
evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)
extrafont * 0.19 2023-01-18 [1] CRAN (R 4.3.0)
extrafontdb 1.0 2012-06-11 [1] CRAN (R 4.3.0)
fansi 1.0.4 2023-01-22 [1] CRAN (R 4.3.0)
farver 2.1.1 2022-07-06 [1] CRAN (R 4.3.0)
fastICA 1.2-3 2021-09-25 [1] CRAN (R 4.3.0)
fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)
forcats * 1.0.0.9000 2023-04-23 [1] Github (tidyverse/forcats@4a8525a)
foreach 1.5.2 2022-02-02 [1] CRAN (R 4.3.0)
fs 1.6.3 2023-07-20 [1] CRAN (R 4.3.1)
generics 0.1.3 2022-07-05 [1] CRAN (R 4.3.0)
GetoptLong 1.0.5 2020-12-15 [1] CRAN (R 4.3.0)
ggplot2 * 3.4.2.9000 2023-08-11 [1] Github (tidyverse/ggplot2@2cd0e96)
ggrepel 0.9.3 2023-02-03 [1] CRAN (R 4.3.0)
ggthemes 4.2.4 2021-01-20 [1] CRAN (R 4.3.0)
GlobalOptions 0.1.2 2020-06-10 [1] CRAN (R 4.3.0)
glue 1.6.2.9000 2023-04-23 [1] Github (tidyverse/glue@cbac82a)
gridExtra 2.3 2017-09-09 [1] CRAN (R 4.3.0)
gt 0.9.0.9000 2023-08-11 [1] Github (rstudio/gt@a3cc005)
gtable 0.3.3.9000 2023-04-23 [1] Github (r-lib/gtable@c56fd4f)
hms 1.1.3 2023-03-21 [1] CRAN (R 4.3.0)
HSMMSingleCell 1.20.0 2023-04-27 [1] Bioconductor
htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.1)
htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)
igraph 1.5.1 2023-08-10 [1] CRAN (R 4.3.1)
IRanges 2.34.1 2023-06-22 [1] Bioconductor
irlba 2.3.5.1 2022-10-03 [1] CRAN (R 4.3.0)
iterators 1.0.14 2022-02-05 [1] CRAN (R 4.3.0)
jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.1)
knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)
labeling 0.4.2 2020-10-20 [1] CRAN (R 4.3.0)
lattice 0.21-8 2023-04-05 [2] CRAN (R 4.3.1)
leidenbase 0.1.25 2023-07-19 [1] CRAN (R 4.3.1)
lifecycle 1.0.3 2022-10-07 [1] CRAN (R 4.3.0)
limma 3.56.2 2023-06-04 [1] Bioconductor
lubridate * 1.9.2.9000 2023-07-22 [1] Github (tidyverse/lubridate@cae67ea)
magick 2.7.5 2023-08-07 [1] CRAN (R 4.3.1)
magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.3.0)
markdown 1.7 2023-05-16 [1] CRAN (R 4.3.0)
Matrix * 1.6-0 2023-07-08 [2] CRAN (R 4.3.1)
matrixStats 1.0.0 2023-06-02 [1] CRAN (R 4.3.0)
memoise 2.0.1 2021-11-26 [1] CRAN (R 4.3.0)
monocle 2.28.0 2023-04-25 [1] Bioconductor
munsell 0.5.0 2018-06-12 [1] CRAN (R 4.3.0)
paletteer 1.5.0 2022-10-19 [1] CRAN (R 4.3.0)
patchwork * 1.1.2.9000 2023-08-11 [1] Github (thomasp85/patchwork@bd57553)
pheatmap 1.0.12 2019-01-04 [1] CRAN (R 4.3.0)
pillar 1.9.0 2023-03-22 [1] CRAN (R 4.3.0)
pkgbuild 1.4.2 2023-06-26 [1] CRAN (R 4.3.1)
pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.3.0)
pkgload 1.3.2.9000 2023-07-05 [1] Github (r-lib/pkgload@3cf9896)
plyr 1.8.8 2022-11-11 [1] CRAN (R 4.3.0)
png 0.1-8 2022-11-29 [1] CRAN (R 4.3.0)
prettyunits 1.1.1.9000 2023-04-23 [1] Github (r-lib/prettyunits@8706d89)
prismatic 1.1.1 2022-08-15 [1] CRAN (R 4.3.0)
processx 3.8.2 2023-06-30 [1] CRAN (R 4.3.1)
ps 1.7.5 2023-04-18 [1] CRAN (R 4.3.0)
purrr * 1.0.2.9000 2023-08-11 [1] Github (tidyverse/purrr@ac4f5a9)
qlcMatrix 0.9.7 2018-04-20 [1] CRAN (R 4.3.0)
R.cache 0.16.0 2022-07-21 [1] CRAN (R 4.3.0)
R.methodsS3 1.8.2 2022-06-13 [1] CRAN (R 4.3.0)
R.oo 1.25.0 2022-06-12 [1] CRAN (R 4.3.0)
R.utils 2.12.2 2022-11-11 [1] CRAN (R 4.3.0)
R6 2.5.1.9000 2023-04-23 [1] Github (r-lib/R6@e97cca7)
ragg 1.2.5 2023-01-12 [1] CRAN (R 4.3.0)
RANN 2.6.1 2019-01-08 [1] CRAN (R 4.3.0)
RColorBrewer 1.1-3 2022-04-03 [1] CRAN (R 4.3.0)
Rcpp 1.0.11 2023-07-06 [1] CRAN (R 4.3.1)
readr * 2.1.4.9000 2023-08-03 [1] Github (tidyverse/readr@80e4dc1)
rematch2 2.1.2 2020-05-01 [1] CRAN (R 4.3.0)
remotes 2.4.2.9000 2023-06-09 [1] Github (r-lib/remotes@8875171)
reshape2 1.4.4 2020-04-09 [1] CRAN (R 4.3.0)
rjson 0.2.21 2022-01-09 [1] CRAN (R 4.3.0)
rlang 1.1.1.9000 2023-06-09 [1] Github (r-lib/rlang@c55f602)
rmarkdown 2.23.4 2023-07-27 [1] Github (rstudio/rmarkdown@054d735)
rstudioapi 0.15.0.9000 2023-07-19 [1] Github (rstudio/rstudioapi@feceaef)
Rtsne 0.17 2023-04-23 [1] Github (jkrijthe/Rtsne@ca6f630)
Rttf2pt1 1.3.12 2023-01-22 [1] CRAN (R 4.3.0)
S4Vectors 0.38.1 2023-05-02 [1] Bioconductor
sass 0.4.7 2023-07-15 [1] CRAN (R 4.3.1)
scales 1.2.1 2022-08-20 [1] CRAN (R 4.3.0)
sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)
shape 1.4.6 2021-05-19 [1] CRAN (R 4.3.0)
slam 0.1-50 2022-01-08 [1] CRAN (R 4.3.0)
sparsesvd 0.2-2 2023-01-14 [1] CRAN (R 4.3.0)
stringi 1.7.12 2023-01-11 [1] CRAN (R 4.3.0)
stringr * 1.5.0.9000 2023-08-11 [1] Github (tidyverse/stringr@08ff36f)
styler * 1.10.1 2023-07-17 [1] Github (r-lib/styler@aca7223)
systemfonts 1.0.4 2022-02-11 [1] CRAN (R 4.3.0)
textshaping 0.3.6 2021-10-13 [1] CRAN (R 4.3.0)
tibble * 3.2.1.9005 2023-05-28 [1] Github (tidyverse/tibble@4de5c15)
tidyr * 1.3.0.9000 2023-04-23 [1] Github (tidyverse/tidyr@0764e65)
tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.3.0)
tidyverse * 2.0.0.9000 2023-04-23 [1] Github (tidyverse/tidyverse@8ec2e1f)
timechange 0.2.0 2023-01-11 [1] CRAN (R 4.3.0)
tzdb 0.4.0 2023-05-12 [1] CRAN (R 4.3.0)
usethis 2.2.2.9000 2023-07-11 [1] Github (r-lib/usethis@467ff57)
utf8 1.2.3 2023-01-31 [1] CRAN (R 4.3.0)
vctrs 0.6.3 2023-06-14 [1] CRAN (R 4.3.0)
VGAM 1.1-8 2023-03-09 [1] CRAN (R 4.3.0)
viridis 0.6.4 2023-07-22 [1] CRAN (R 4.3.1)
viridisLite 0.4.2 2023-05-02 [1] CRAN (R 4.3.0)
vroom 1.6.3.9000 2023-04-30 [1] Github (tidyverse/vroom@89b6aac)
wesanderson 0.3.6.9000 2023-07-25 [1] Github (karthik/wesanderson@95d49de)
withr 2.5.0 2022-03-03 [1] CRAN (R 4.3.0)
xfun 0.40 2023-08-09 [1] CRAN (R 4.3.1)
xml2 1.3.5 2023-07-06 [1] CRAN (R 4.3.1)
yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)
[1] /opt/homebrew/lib/R/4.3/site-library
[2] /opt/homebrew/Cellar/r/4.3.1/lib/R/library
──────────────────────────────────────────────────────────────────────────────Styling 1 files:
global_reprogramming_of_transcription.qmd ✔
─────────────────────────────────────────
Status Count Legend
✔ 1 File unchanged.
ℹ 0 File changed.
✖ 0 Styling threw an error.
─────────────────────────────────────────@article{duan2023,
author = {Duan, Jialei and Li, Boxun and Bhakta, Minoti and Xie, Shiqi
and Zhou, Pei and V. Munshi, Nikhil and C. Hon, Gary},
publisher = {Cell Press},
title = {Rational {Reprogramming} of {Cellular} {States} by
{Combinatorial} {Perturbation}},
journal = {Cell reports},
volume = {27},
number = {12},
pages = {3486 - 3499000000},
date = {2023-08-12},
url = {https://doi.org/10.1016/j.celrep.2019.05.079},
doi = {10.1016/j.celrep.2019.05.079},
langid = {en},
abstract = {Reprogram-Seq leverages organ-specific cell atlas data
with single-cell perturbation and computational analysis to predict,
evaluate, and optimize TF combinations that reprogram a cell type of
interest.}
}