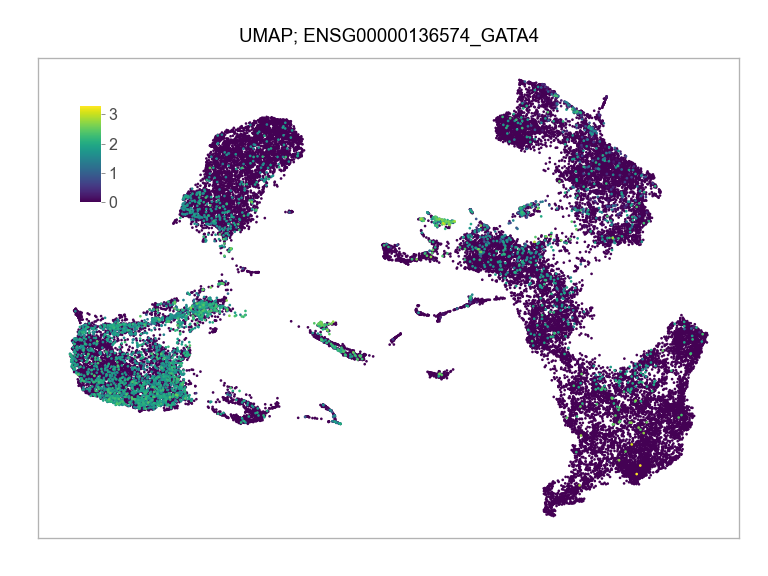
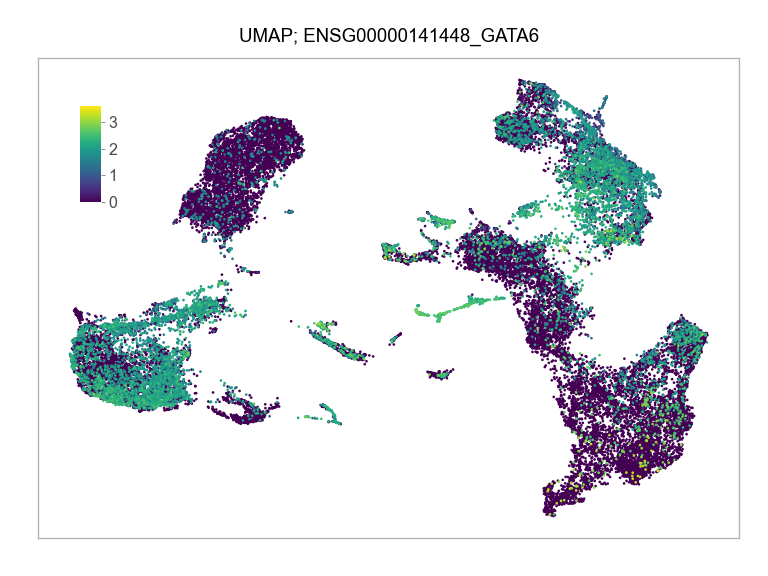
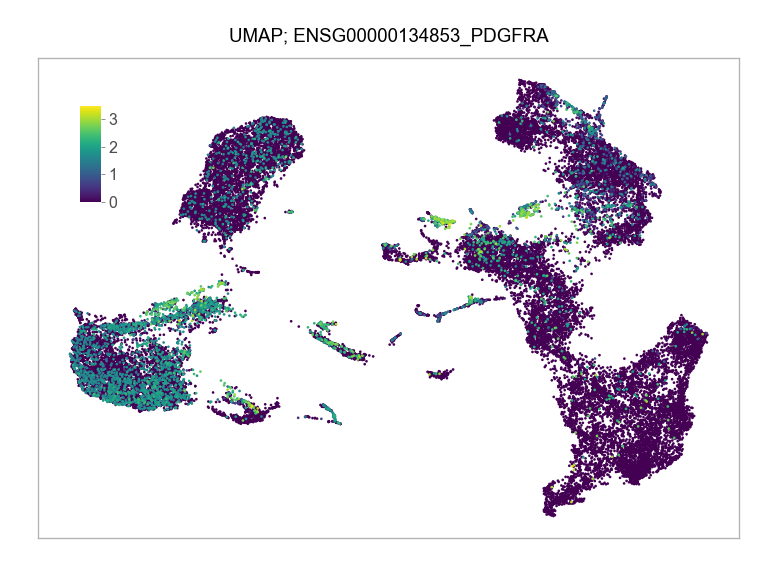
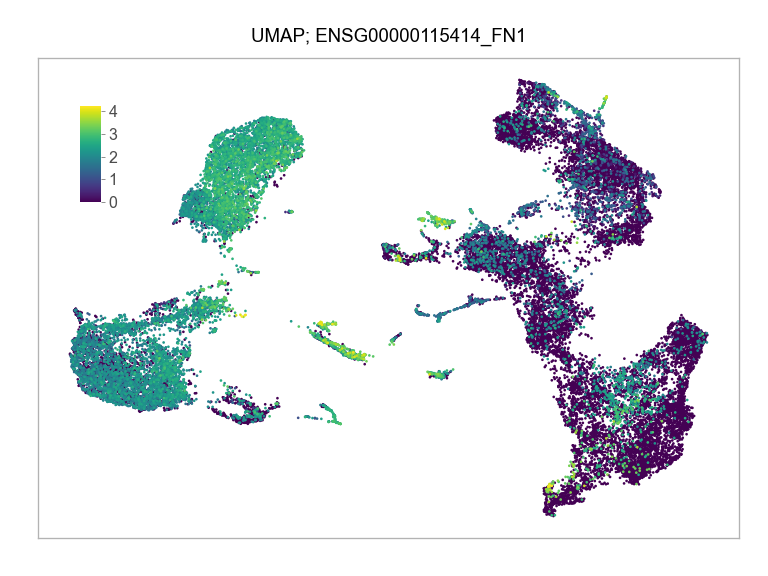
Sys.time()[1] "2023-02-25 17:07:22 CST"Sys.time()[1] "2023-02-25 17:07:22 CST"[1] "America/Chicago"import multiprocessing
import sys
sys.path.append("/Users/jialei/Dropbox/Data/Projects/UTSW/Scripts/utilities")
sys.path.append("/project/GCRB/Hon_lab/s166631/00.bin/utilities/")
from pathlib import Path
from random import sample
import harmonypy as hm
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import phate
import scanpy as sc
import umap
from utilities import (
plot_embedding,
plot_pca_variance_explained,
plot_cluster_composition,
)params = {
"pdf.fonttype": 42,
"font.family": "sans-serif",
"font.sans-serif": "Arial",
"mathtext.default": "regular",
"figure.dpi": 96 * 1.5,
}
plt.rcParams.update(params)PROJECT_DIR = Path(
"/Users/jialei/Dropbox/Data/Projects/UTSW/Peri-implantation") / "raw"
SEED = 20210719
N_COMPONENTS = 100
MINIMAL_NUM_GENES_REQUIRED_FOR_CELL = 200
MINIMAL_NUM_CELLS_REQUIRED_FOR_GENE = 30
MINIMAL_NUM_COUNTS_REQUIRED_FOR_GENE = 60
MT_PERCENTAGE_CUTOFF = 0.2
N_THREADS = multiprocessing.cpu_count() - 1
N_SAMPLING = NoneThis study
# This study; LW119_LW120_LW121_LW122
libraries = ["LW119", "LW120", "LW121", "LW122"]
adatas = [
sc.read_h5ad(filename=PROJECT_DIR / i / "matrix" / "adata.h5ad")
for i in libraries
]Yu et al. 2021
# Yu et al. 2021; PRJNA632839; LW60_LW61
adata = sc.read_h5ad(
filename=PROJECT_DIR
/ "PRJNA632839/LW36_LW58_LW59_LW60_LW61"
/ "matrix"
/ "adata.h5ad"
)
adatas.append(adata[adata.obs["batch"].isin(["LW60", "LW61"]), :])
# filter mt_percentage
adatas = [
i[
i.obs["mt_percentage"] <= MT_PERCENTAGE_CUTOFF,
]
for i in adatas
]Public
# Petropoulos et al. 2016; PRJEB11202
# Xiang et al. 2020; PRJNA562548
# Tyser et al. 2021; PRJEB40781
# Zheng et al. 2019; PRJNA555602
# Yanagida et al. 2021; PRJNA720968
libraries = [
"PRJEB11202",
"PRJNA562548",
"PRJEB40781",
"PRJNA555602",
"PRJNA720968",
]
adatas_public = [
sc.read_h5ad(filename=PROJECT_DIR / "public" / i / "matrix" / "adata.h5ad")
for i in libraries
]
adatas.extend(adatas_public)
del adatas_public# merge adatas
adata = sc.concat(adatas, axis=0)print(f"Raw median UMIs per cell: {np.median(a=adata.X.sum(axis=1).A1):,}")
## Raw median UMIs per cell: 19,032.0
print(f"Number of cells before filtering: {adata.n_obs:,}")
## Number of cells before filtering: 31,481
print(f"Number of features before filtering: {adata.n_vars:,}")
## Number of features before filtering: 33,538
print(adata.obs["batch"].value_counts())
## GSM3956280 5454
## LW61 5156
## LW121 5130
## GSM3956281 4512
## LW60 4497
## LW119 2236
## PRJEB11202 1529
## PRJEB40781 1195
## PRJNA562548 555
## PRJNA720968 495
## LW120 435
## LW122 287
## Name: batch, dtype: int64# reorder cells
adata = adata[np.sort(adata.obs.index), :]
# filter cells
adata = adata[
(adata.X > 0).sum(axis=1).A1 >= MINIMAL_NUM_GENES_REQUIRED_FOR_CELL, :
]matrix_cpm_use = adata.X.transpose(copy=True)
features = adata.var_names# sample cells
if N_SAMPLING:
adata = adata[sample(list(adata.obs.index.values), N_SAMPLING), :]
print(f"Number of cells after sampling: {adata.n_obs:,}")
# filter features
row_idx = np.logical_and(
(adata.X > 0).sum(axis=0).A1 >= MINIMAL_NUM_CELLS_REQUIRED_FOR_GENE,
(adata.X).sum(axis=0).A1 >= MINIMAL_NUM_COUNTS_REQUIRED_FOR_GENE,
)
adata = adata[:, row_idx]print(f"Median UMIs per cell: {np.median(a=adata.X.sum(axis=1).A1):,}")
## Median UMIs per cell: 19,032.0
print(f"Number of cells after filtering: {adata.n_obs:,}")
## Number of cells after filtering: 31,481
print(f"Number of features after filtering: {adata.n_vars:,}")
## Number of features after filtering: 26,297# normalize
sc.pp.normalize_total(
adata=adata,
target_sum=np.median(a=adata.X.sum(axis=1).A1),
exclude_highly_expressed=False,
)/Users/jialei/.pyenv/versions/mambaforge-22.9.0-3/lib/python3.10/site-packages/scanpy/preprocessing/_normalization.py:138: UserWarning: Revieved a view of an AnnData. Making a copy.
view_to_actual(adata)
/Users/jialei/.pyenv/versions/mambaforge-22.9.0-3/lib/python3.10/site-packages/scanpy/preprocessing/_normalization.py:138: FutureWarning: X.dtype being converted to np.float32 from int64. In the next version of anndata (0.9) conversion will not be automatic. Pass dtype explicitly to avoid this warning. Pass `AnnData(X, dtype=X.dtype, ...)` to get the future behavour.
view_to_actual(adata)# logarithmize
sc.pp.log1p(adata)# detect hvgs
if HVG:
sc.pp.highly_variable_genes(
adata,
min_mean=0.0125,
max_mean=3,
min_disp=0.5,
flavor="seurat",
batch_key="batch",
)
# standardize/Users/jialei/.pyenv/versions/mambaforge-22.9.0-3/lib/python3.10/site-packages/scanpy/preprocessing/_highly_variable_genes.py:475: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
hvg = hvg.append(missing_hvg, ignore_index=True)
/Users/jialei/.pyenv/versions/mambaforge-22.9.0-3/lib/python3.10/site-packages/scanpy/preprocessing/_highly_variable_genes.py:475: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
hvg = hvg.append(missing_hvg, ignore_index=True)
/Users/jialei/.pyenv/versions/mambaforge-22.9.0-3/lib/python3.10/site-packages/scanpy/preprocessing/_highly_variable_genes.py:475: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
hvg = hvg.append(missing_hvg, ignore_index=True)
/Users/jialei/.pyenv/versions/mambaforge-22.9.0-3/lib/python3.10/site-packages/scanpy/preprocessing/_highly_variable_genes.py:475: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
hvg = hvg.append(missing_hvg, ignore_index=True)
/Users/jialei/.pyenv/versions/mambaforge-22.9.0-3/lib/python3.10/site-packages/scanpy/preprocessing/_highly_variable_genes.py:475: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
hvg = hvg.append(missing_hvg, ignore_index=True)
/Users/jialei/.pyenv/versions/mambaforge-22.9.0-3/lib/python3.10/site-packages/scanpy/preprocessing/_highly_variable_genes.py:475: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
hvg = hvg.append(missing_hvg, ignore_index=True)
/Users/jialei/.pyenv/versions/mambaforge-22.9.0-3/lib/python3.10/site-packages/scanpy/preprocessing/_highly_variable_genes.py:475: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
hvg = hvg.append(missing_hvg, ignore_index=True)
/Users/jialei/.pyenv/versions/mambaforge-22.9.0-3/lib/python3.10/site-packages/scanpy/preprocessing/_highly_variable_genes.py:475: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
hvg = hvg.append(missing_hvg, ignore_index=True)
/Users/jialei/.pyenv/versions/mambaforge-22.9.0-3/lib/python3.10/site-packages/scanpy/preprocessing/_highly_variable_genes.py:475: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
hvg = hvg.append(missing_hvg, ignore_index=True)
/Users/jialei/.pyenv/versions/mambaforge-22.9.0-3/lib/python3.10/site-packages/scanpy/preprocessing/_highly_variable_genes.py:475: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
hvg = hvg.append(missing_hvg, ignore_index=True)
/Users/jialei/.pyenv/versions/mambaforge-22.9.0-3/lib/python3.10/site-packages/scanpy/preprocessing/_highly_variable_genes.py:475: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
hvg = hvg.append(missing_hvg, ignore_index=True)
/Users/jialei/.pyenv/versions/mambaforge-22.9.0-3/lib/python3.10/site-packages/scanpy/preprocessing/_highly_variable_genes.py:475: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
hvg = hvg.append(missing_hvg, ignore_index=True)sc.pp.scale(
adata,
zero_center=ZERO_CENTER,
max_value=None,
copy=False,
layer=None,
obsm=None,
)sc.tl.pca(
adata,
n_comps=N_COMPONENTS,
zero_center=ZERO_CENTER,
svd_solver="arpack",
random_state=SEED,
return_info=False,
use_highly_variable=HVG,
dtype="float64",
copy=False,
chunked=False,
)
principal_components = adata.obsm["X_pca"]with plt.style.context("ggplot"):
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(5, 2.5))
plot_pca_variance_explained(
x=adata.uns["pca"]["variance_ratio"],
num_pcs=30,
ax=ax,
)
ax.set(ylim=(-0.0025, max(ax.get_ylim())))
plt.tight_layout()
plt.show()
plt.close(fig=fig)<AxesSubplot: xlabel='Principal component', ylabel='Explained variance ratio'>
[(-0.0025, 0.049999999999999996)]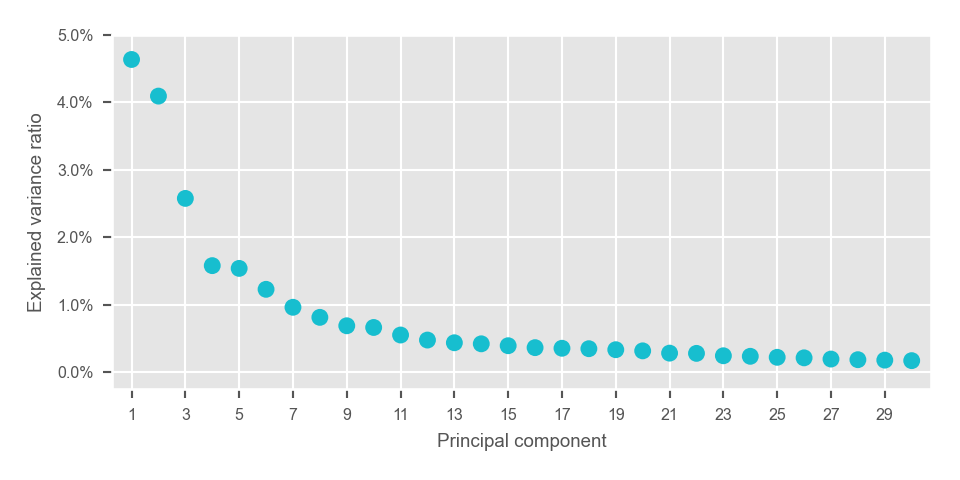
# remove batch effect
batches = adata.obs["batch"].values
print(adata.obs["batch"].value_counts())GSM3956280 5454
LW61 5156
LW121 5130
GSM3956281 4512
LW60 4497
LW119 2236
PRJEB11202 1529
PRJEB40781 1195
PRJNA562548 555
PRJNA720968 495
LW120 435
LW122 287
Name: batch, dtype: int64if len(set(batches)) > 1:
ho = hm.run_harmony(
data_mat=principal_components,
meta_data=pd.DataFrame(
{"batch": batches}, index=adata.obs.index.values
),
vars_use="batch",
random_state=SEED,
)
principal_components_selected = ho.Z_corr.T.astype(np.float64)
else:
principal_components_selected = principal_components.astype(np.float64)2023-02-25 17:08:20,808 - harmonypy - INFO - Iteration 1 of 10
2023-02-25 17:08:28,362 - harmonypy - INFO - Iteration 2 of 10
2023-02-25 17:08:35,736 - harmonypy - INFO - Converged after 2 iterationsprincipal_components_use = principal_components_selected[:, range(16)]embedding_umap = umap.UMAP(
n_neighbors=15,
n_components=2,
metric="euclidean",
min_dist=0.1,
spread=1.0,
random_state=SEED,
transform_seed=42,
verbose=True,
).fit_transform(principal_components_use)UMAP(random_state=20210719, verbose=True)
Sat Feb 25 17:08:37 2023 Construct fuzzy simplicial set
Sat Feb 25 17:08:37 2023 Finding Nearest Neighbors
Sat Feb 25 17:08:37 2023 Building RP forest with 14 trees
Sat Feb 25 17:08:37 2023 NN descent for 15 iterations
1 / 15
2 / 15
3 / 15
Stopping threshold met -- exiting after 3 iterations
Sat Feb 25 17:08:44 2023 Finished Nearest Neighbor Search
Sat Feb 25 17:08:45 2023 Construct embedding
Sat Feb 25 17:08:57 2023 Finished embedding
Epochs completed: 0%| 0/200 [00:00]
Epochs completed: 0%| 1/200 [00:00]
Epochs completed: 2%| 2 5/200 [00:00]
Epochs completed: 4%| 3 7/200 [00:00]
Epochs completed: 4%| 4 9/200 [00:00]
Epochs completed: 6%| 5 11/200 [00:00]
Epochs completed: 6%| 6 13/200 [00:00]
Epochs completed: 8%| 7 15/200 [00:00]
Epochs completed: 8%| 8 17/200 [00:01]
Epochs completed: 10%| 9 19/200 [00:01]
Epochs completed: 10%| # 21/200 [00:01]
Epochs completed: 12%| #1 23/200 [00:01]
Epochs completed: 12%| #2 25/200 [00:01]
Epochs completed: 14%| #3 27/200 [00:01]
Epochs completed: 14%| #4 29/200 [00:01]
Epochs completed: 16%| #5 31/200 [00:01]
Epochs completed: 16%| #6 33/200 [00:01]
Epochs completed: 18%| #7 35/200 [00:02]
Epochs completed: 18%| #8 37/200 [00:02]
Epochs completed: 20%| #9 39/200 [00:02]
Epochs completed: 20%| ## 41/200 [00:02]
Epochs completed: 22%| ##1 43/200 [00:02]
Epochs completed: 22%| ##2 45/200 [00:02]
Epochs completed: 24%| ##3 47/200 [00:02]
Epochs completed: 24%| ##4 49/200 [00:02]
Epochs completed: 26%| ##5 51/200 [00:02]
Epochs completed: 26%| ##6 53/200 [00:03]
Epochs completed: 28%| ##7 55/200 [00:03]
Epochs completed: 28%| ##8 57/200 [00:03]
Epochs completed: 30%| ##9 59/200 [00:03]
Epochs completed: 30%| ### 61/200 [00:03]
Epochs completed: 32%| ###1 63/200 [00:03]
Epochs completed: 32%| ###2 65/200 [00:03]
Epochs completed: 34%| ###3 67/200 [00:03]
Epochs completed: 34%| ###4 69/200 [00:03]
Epochs completed: 36%| ###5 71/200 [00:04]
Epochs completed: 36%| ###6 73/200 [00:04]
Epochs completed: 38%| ###7 75/200 [00:04]
Epochs completed: 38%| ###8 77/200 [00:04]
Epochs completed: 40%| ###9 79/200 [00:04]
Epochs completed: 40%| #### 81/200 [00:04]
Epochs completed: 42%| ####1 83/200 [00:04]
Epochs completed: 42%| ####2 85/200 [00:04]
Epochs completed: 44%| ####3 87/200 [00:04]
Epochs completed: 44%| ####4 89/200 [00:05]
Epochs completed: 46%| ####5 91/200 [00:05]
Epochs completed: 46%| ####6 93/200 [00:05]
Epochs completed: 48%| ####7 95/200 [00:05]
Epochs completed: 48%| ####8 97/200 [00:05]
Epochs completed: 50%| ####9 99/200 [00:05]
Epochs completed: 50%| ##### 101/200 [00:05]
Epochs completed: 52%| #####1 103/200 [00:05]
Epochs completed: 52%| #####2 105/200 [00:05]
Epochs completed: 54%| #####3 107/200 [00:06]
Epochs completed: 55%| #####4 109/200 [00:06]
Epochs completed: 56%| #####5 111/200 [00:06]
Epochs completed: 56%| #####6 113/200 [00:06]
Epochs completed: 57%| #####7 115/200 [00:06]
Epochs completed: 58%| #####8 117/200 [00:06]
Epochs completed: 60%| #####9 119/200 [00:06]
Epochs completed: 60%| ###### 121/200 [00:06]
Epochs completed: 62%| ######1 123/200 [00:06]
Epochs completed: 62%| ######2 125/200 [00:07]
Epochs completed: 64%| ######3 127/200 [00:07]
Epochs completed: 64%| ######4 129/200 [00:07]
Epochs completed: 66%| ######5 131/200 [00:07]
Epochs completed: 66%| ######6 133/200 [00:07]
Epochs completed: 68%| ######7 135/200 [00:07]
Epochs completed: 68%| ######8 137/200 [00:07]
Epochs completed: 70%| ######9 139/200 [00:07]
Epochs completed: 70%| ####### 141/200 [00:07]
Epochs completed: 72%| #######1 143/200 [00:08]
Epochs completed: 72%| #######2 145/200 [00:08]
Epochs completed: 74%| #######3 147/200 [00:08]
Epochs completed: 74%| #######4 149/200 [00:08]
Epochs completed: 76%| #######5 151/200 [00:08]
Epochs completed: 76%| #######6 153/200 [00:08]
Epochs completed: 78%| #######7 155/200 [00:08]
Epochs completed: 78%| #######8 157/200 [00:08]
Epochs completed: 80%| #######9 159/200 [00:08]
Epochs completed: 80%| ######## 161/200 [00:09]
Epochs completed: 82%| ########1 163/200 [00:09]
Epochs completed: 82%| ########2 165/200 [00:09]
Epochs completed: 84%| ########3 167/200 [00:09]
Epochs completed: 84%| ########4 169/200 [00:09]
Epochs completed: 86%| ########5 171/200 [00:09]
Epochs completed: 86%| ########6 173/200 [00:09]
Epochs completed: 88%| ########7 175/200 [00:09]
Epochs completed: 88%| ########8 177/200 [00:09]
Epochs completed: 90%| ########9 179/200 [00:10]
Epochs completed: 90%| ######### 181/200 [00:10]
Epochs completed: 92%| #########1 183/200 [00:10]
Epochs completed: 92%| #########2 185/200 [00:10]
Epochs completed: 94%| #########3 187/200 [00:10]
Epochs completed: 94%| #########4 189/200 [00:10]
Epochs completed: 96%| #########5 191/200 [00:10]
Epochs completed: 96%| #########6 193/200 [00:10]
Epochs completed: 98%| #########7 195/200 [00:10]
Epochs completed: 98%| #########8 197/200 [00:11]
Epochs completed: 100%| #########9 199/200 [00:11]
Epochs completed: 100%| ########## 200/200 [00:11]adata = sc.AnnData(
X=principal_components_use,
obs={"cell": adata.obs.index.values, "batch": batches},
dtype="float64",
)
adata.obs.index = adata.obs["cell"]
sc.pp.neighbors(
adata=adata,
n_neighbors=30,
n_pcs=0,
use_rep=None,
knn=True,
random_state=SEED,
method="umap",
metric="euclidean",
copy=False,
)
sc.tl.leiden(
adata=adata,
resolution=1,
random_state=SEED,
key_added="leiden",
directed=True,
use_weights=True,
partition_type=None,
copy=False,
)embedding = pd.DataFrame(
data=np.concatenate(
(adata.obs[["batch", "leiden"]], embedding_umap),
axis=1,
),
index=adata.obs["cell"],
columns=["batch", "leiden", "x_umap_min_dist=0.1", "y_umap_min_dist=0.1"],
)
embedding = embedding.astype(
{
"leiden": int,
"x_umap_min_dist=0.1": float,
"y_umap_min_dist=0.1": float,
}
)fig, ax = plt.subplots(nrows=1 * 1, ncols=1, figsize=(4 * 1, 3 * 1))
plot_embedding(
embedding=embedding.loc[:, ["x_umap_min_dist=0.1", "y_umap_min_dist=0.1"]],
ax=ax,
color_values=[str(i) for i in embedding["leiden"]],
title="UMAP; Leiden",
show_color_value_labels=True,
rasterise=True,
)
plt.tight_layout()
plt.show()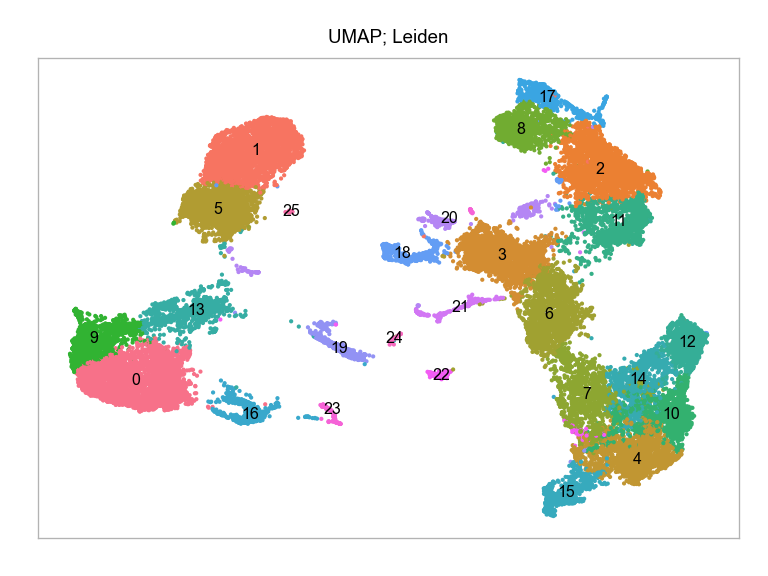
plt.close(fig=fig)embedding.groupby(by="batch").size().to_frame(name="num_cells") num_cells
batch
GSM3956280 5454
GSM3956281 4512
LW119 2236
LW120 435
LW121 5130
LW122 287
LW60 4497
LW61 5156
PRJEB11202 1529
PRJEB40781 1195
PRJNA562548 555
PRJNA720968 495
cluster_composition = (
(
embedding.groupby(by="leiden").aggregate("batch").value_counts()
/ embedding.groupby(by="leiden").aggregate("batch").size()
)
.to_frame(name="percentage")
.reset_index()
)
cluster_composition = cluster_composition.astype({"leiden": str})
clusters_selected = list(
np.sort(embedding["leiden"].unique()).astype(dtype=str)[::-1]
)
batches_selected = list(embedding["batch"].unique())
cluster_composition = cluster_composition.astype(
{
"leiden": pd.api.types.CategoricalDtype(
categories=clusters_selected, ordered=True
),
"batch": pd.api.types.CategoricalDtype(
categories=batches_selected, ordered=True
),
}
)fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(4.5, 4))
plot_cluster_composition(
cluster_composition=cluster_composition,
x="batch",
y="leiden",
ax=ax,
x_order=batches_selected,
y_order=clusters_selected,
)
plt.tight_layout()
plt.show()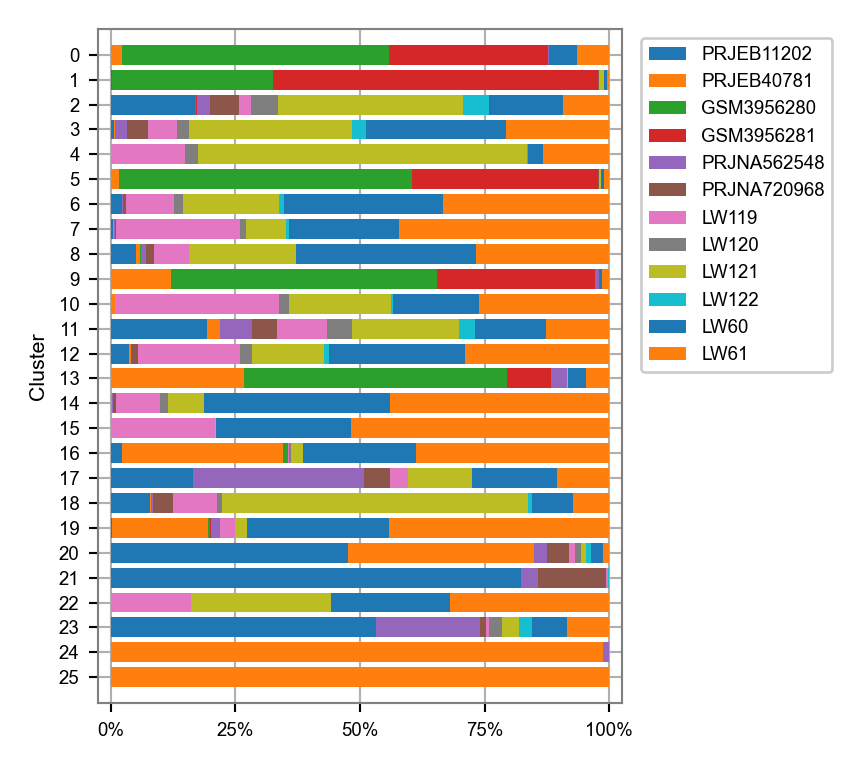
plt.close(fig=fig)matrix_cpm_use.data = (
1_000_000
* matrix_cpm_use.data
/ np.repeat(matrix_cpm_use.sum(axis=0).A1, np.diff(matrix_cpm_use.indptr))
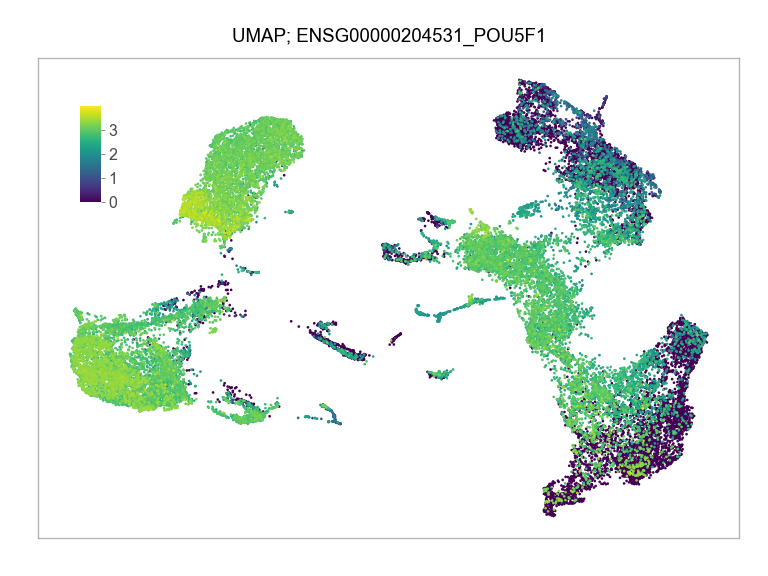
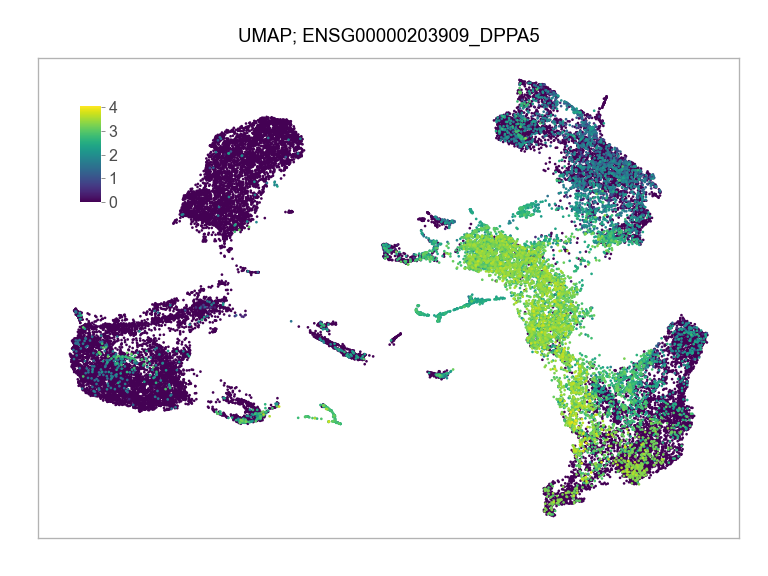
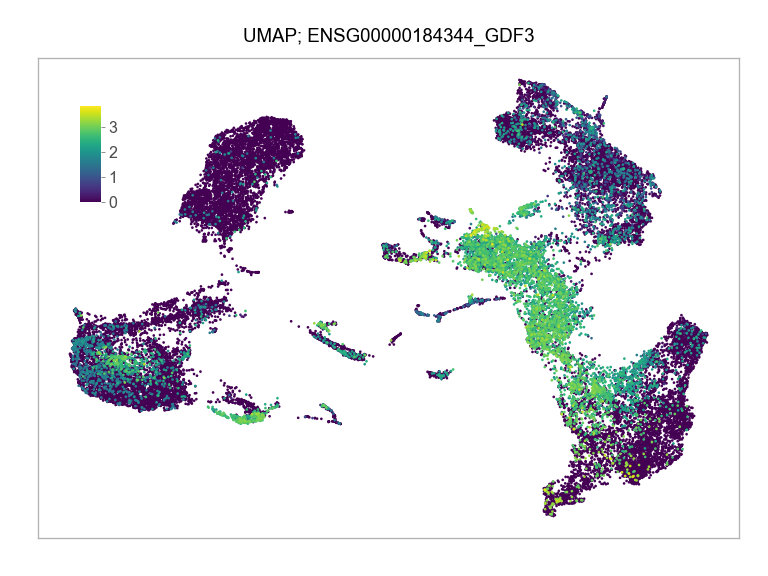
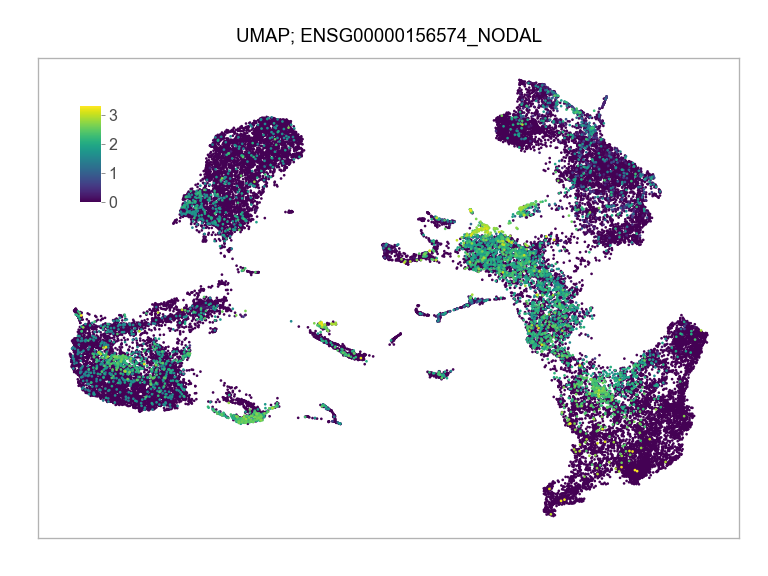
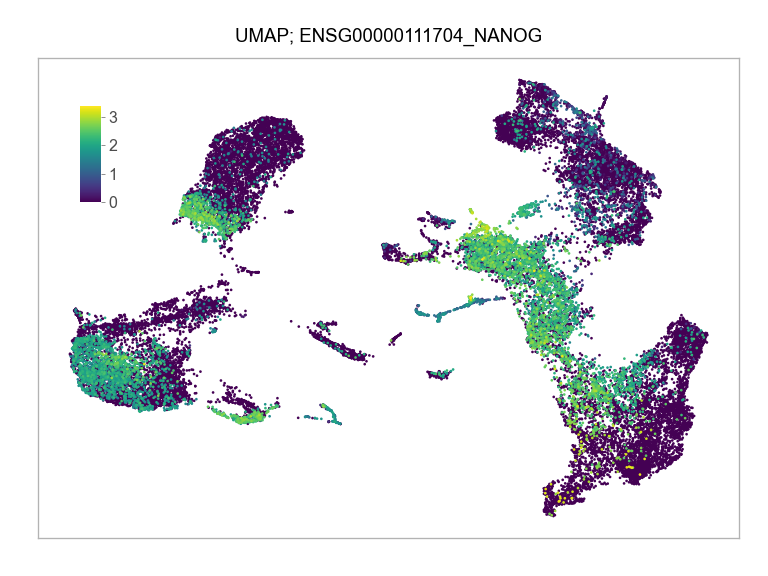
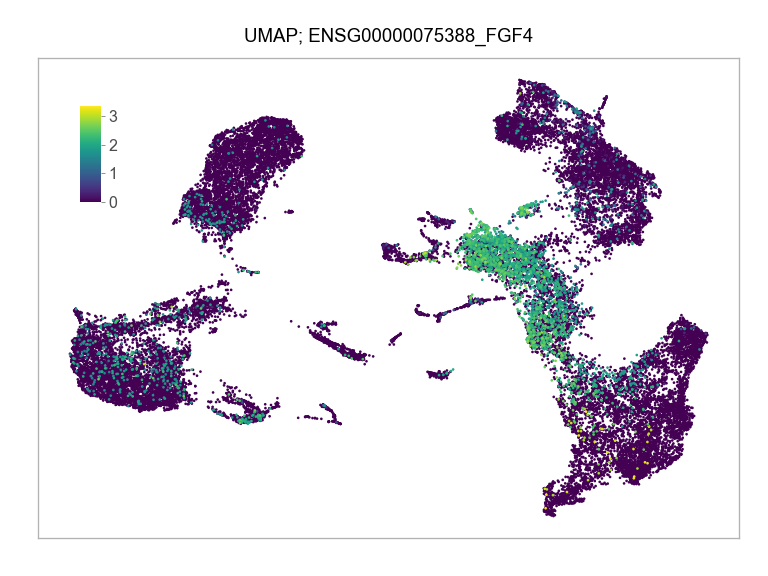
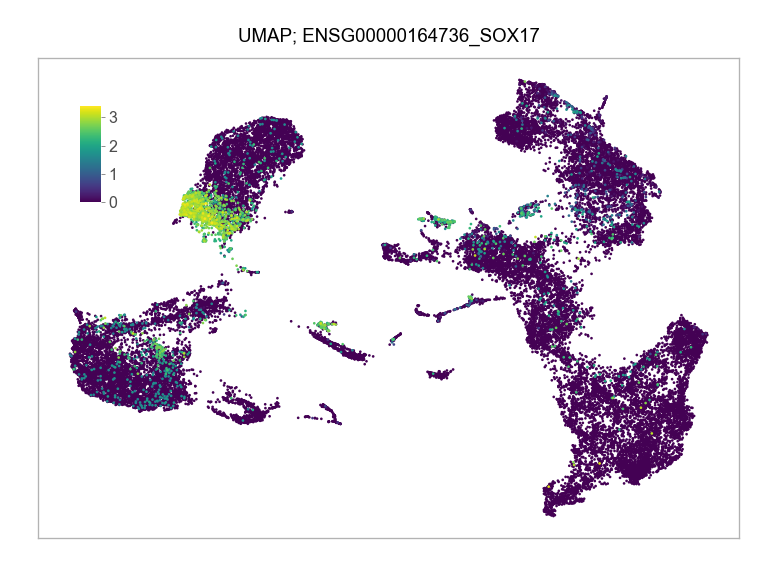
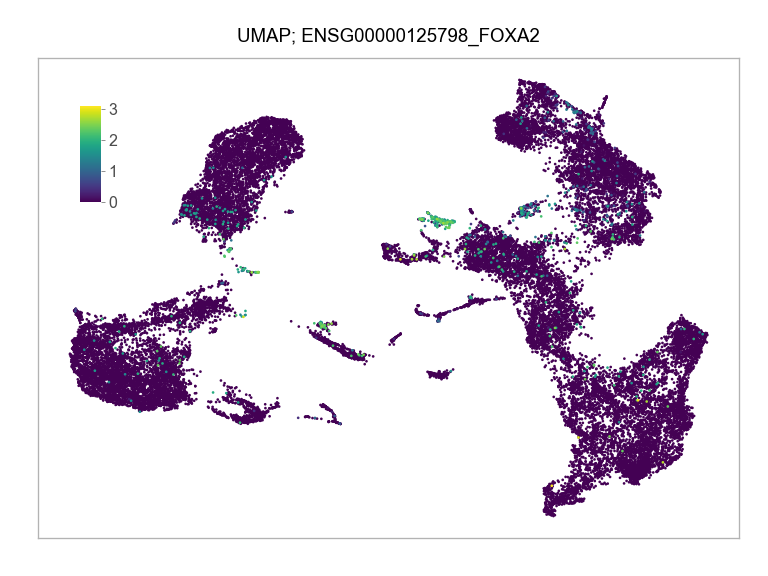
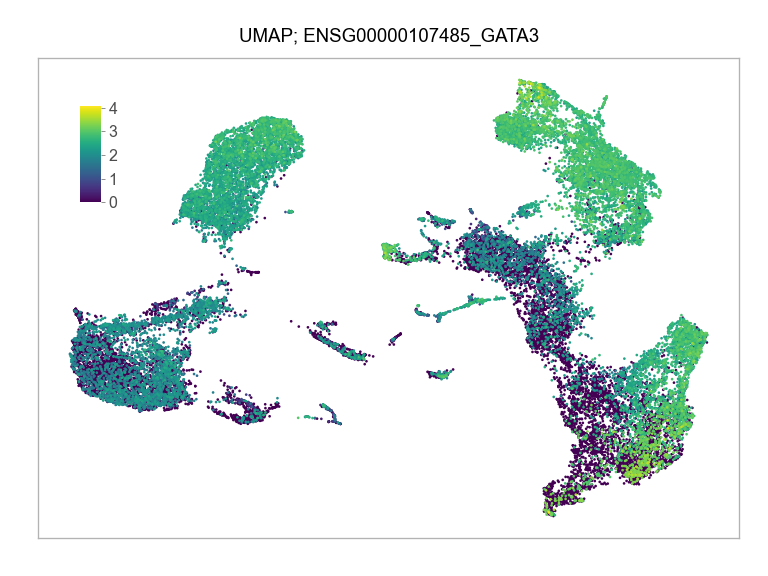
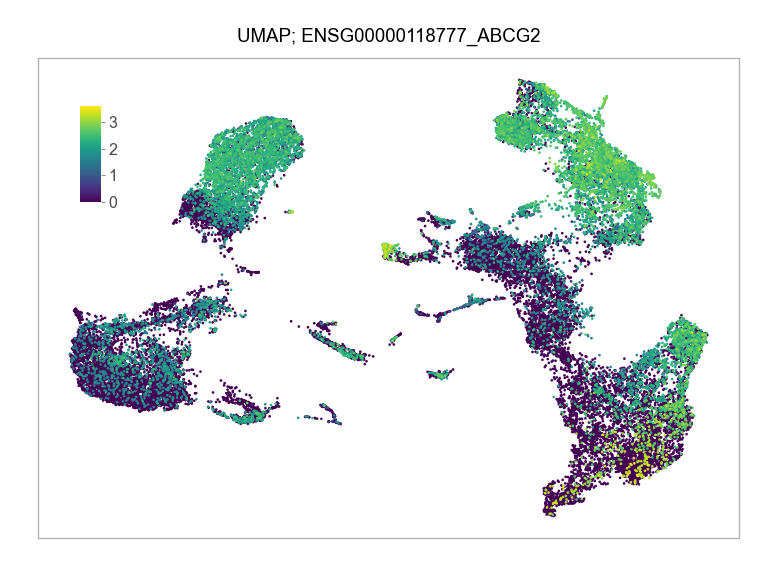
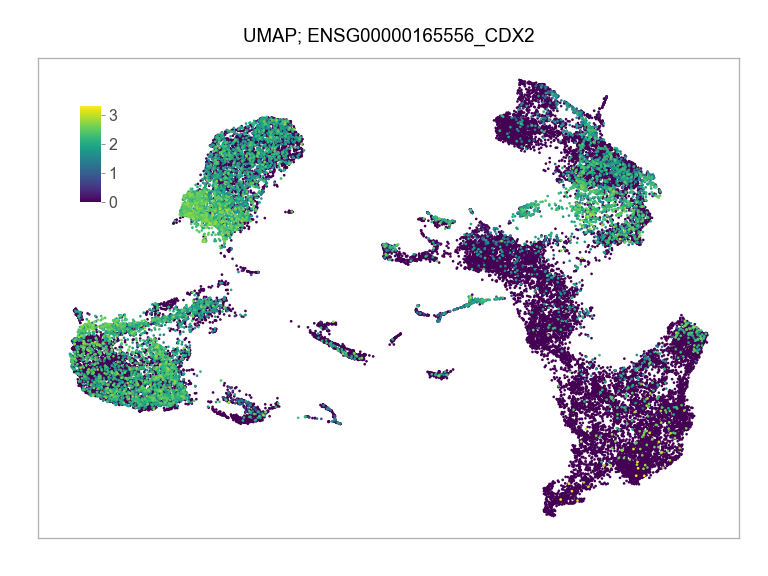
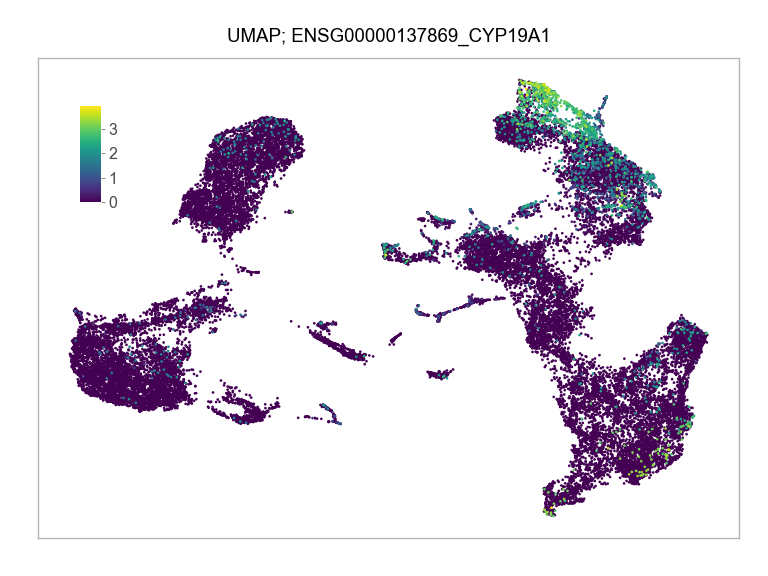
)FEATURES_SELECTED = [
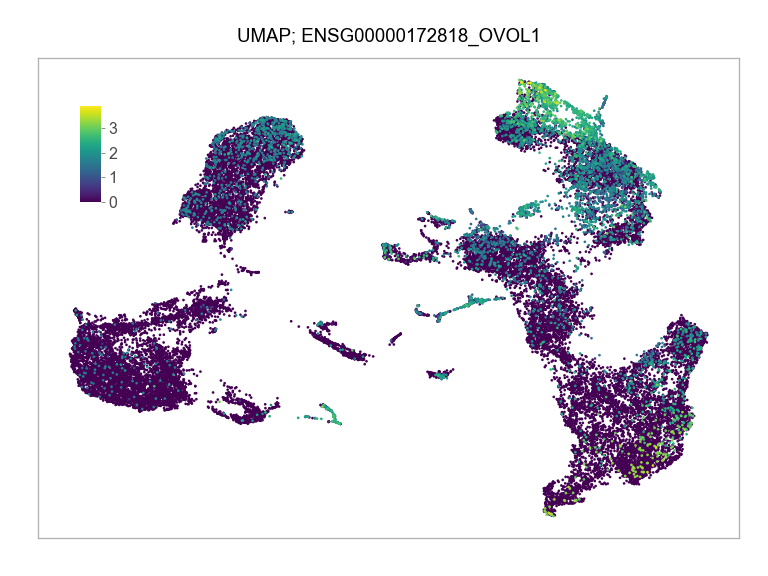
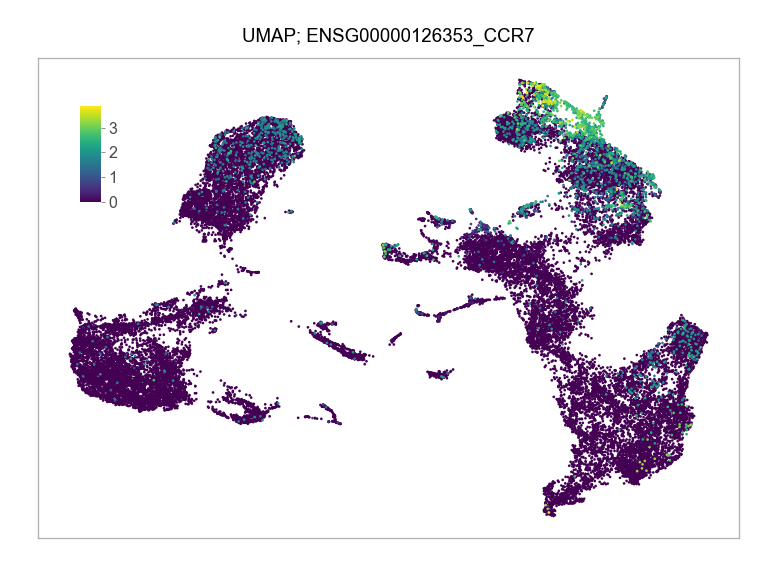
"ENSG00000204531_POU5F1",
"ENSG00000203909_DPPA5",
"ENSG00000184344_GDF3",
"ENSG00000156574_NODAL",
"ENSG00000111704_NANOG",
"ENSG00000075388_FGF4",
#
"ENSG00000164736_SOX17",
"ENSG00000125798_FOXA2",
"ENSG00000136574_GATA4",
"ENSG00000141448_GATA6",
"ENSG00000134853_PDGFRA",
"ENSG00000115414_FN1",
#
"ENSG00000107485_GATA3",
"ENSG00000118777_ABCG2",
"ENSG00000165556_CDX2",
"ENSG00000137869_CYP19A1",
"ENSG00000172818_OVOL1",
"ENSG00000126353_CCR7"
]for selected_feature in FEATURES_SELECTED:
print(selected_feature)
idx = np.where([i == selected_feature for i in features])[0]
values = matrix_cpm_use[idx, :].toarray().flatten()
values = np.log10(values + 1)
fig, ax = plt.subplots(nrows=1 * 1, ncols=1, figsize=(4 * 1, 3 * 1))
p = plot_embedding(
embedding=embedding.loc[
adata.obs.index, ["x_umap_min_dist=0.1", "y_umap_min_dist=0.1"]
],
ax=ax,
color_values=values,
title=f"UMAP; {selected_feature}",
show_color_value_labels=False,
marker_size=4,
sort_values=True,
)
ax_ins = ax.inset_axes((0.06, 0.70, 0.03, 0.2))
cbar = fig.colorbar(
mappable=p,
cax=ax_ins,
orientation="vertical",
label="",
ticks=range(np.ceil(max(values)).astype(int)),
)
cbar.outline.set_linewidth(w=0.2)
cbar.outline.set_visible(b=False)
ax_ins.tick_params(
axis="y",
direction="out",
length=1.5,
width=0.2,
color="#333333",
pad=1.25,
labelsize=6,
labelcolor="#4D4D4D",
)
plt.tight_layout()
plt.show()
plt.close(fig=fig)ENSG00000204531_POU5F1
ENSG00000203909_DPPA5
ENSG00000184344_GDF3
ENSG00000156574_NODAL
ENSG00000111704_NANOG
ENSG00000075388_FGF4
ENSG00000164736_SOX17
ENSG00000125798_FOXA2
ENSG00000136574_GATA4
ENSG00000141448_GATA6
ENSG00000134853_PDGFRA
ENSG00000115414_FN1
ENSG00000107485_GATA3
ENSG00000118777_ABCG2
ENSG00000165556_CDX2
ENSG00000137869_CYP19A1
ENSG00000172818_OVOL1
ENSG00000126353_CCR7